Is Target get the values based on the number of images in the dataset folder?
If you are using torchvision.datasets.ImageFolder, then each subfolder will get an own class index.
On the other hand, if you are using a custom dataset, you are defining the target as you wish.
@ptrblck, I am using the torchvision.datasets.ImageFolder, each subfolder is getting class index serially, but problem is …My batch_size =256(default),for input images >= batch_size my precision values are quite good,for input images<batch_size , my precision values are too bad.
but my prediction is predicting correctly, have a look into this…!
{kind=link}
precision is getting the value by comparing the target and predicted values,for images>batch_size target starting index value is 0s,but for img<batchsize target is starting with 1s …so although prediction is correct for img<256 because of prediction is compared with target my precision is very bad
Can you please tell why this is happening in target for img<256,it will be really helpfull as i am struck in this for longer duration,
github repo which i am referring
I don’t think I really understand the use case.
In the second use case, is your dataset containing less than 256 samples in total?
If that’s the case, I doubt that you will be able to train a deep neural network.
@ptrblck,yeah in total i am using datasets(imagenet) less than batchsize(256)
i am already using the pretrained model trained on image net datasets
while evaluating i got the above result.
can i take samples less than batch_size for evaluation?
Yes, the batch size specified in the DataLoader can be larger than the actual Dataset and you would get a single batch containing all samples as seen here:
class MyDataset(Dataset):
def __init__(self):
self.data = torch.randn(200, 1)
def __getitem__(self, idx):
x = self.data[idx]
return x
def __len__(self):
return len(self.data)
dataset = MyDataset()
loader = DataLoader(dataset, batch_size=256)
for data in loader:
print(data.shape)
> torch.Size([200, 1])
ok,but my concern is …
-
why my precision value is very bad for images less than the batch_size…although my prediction is almost correct
-
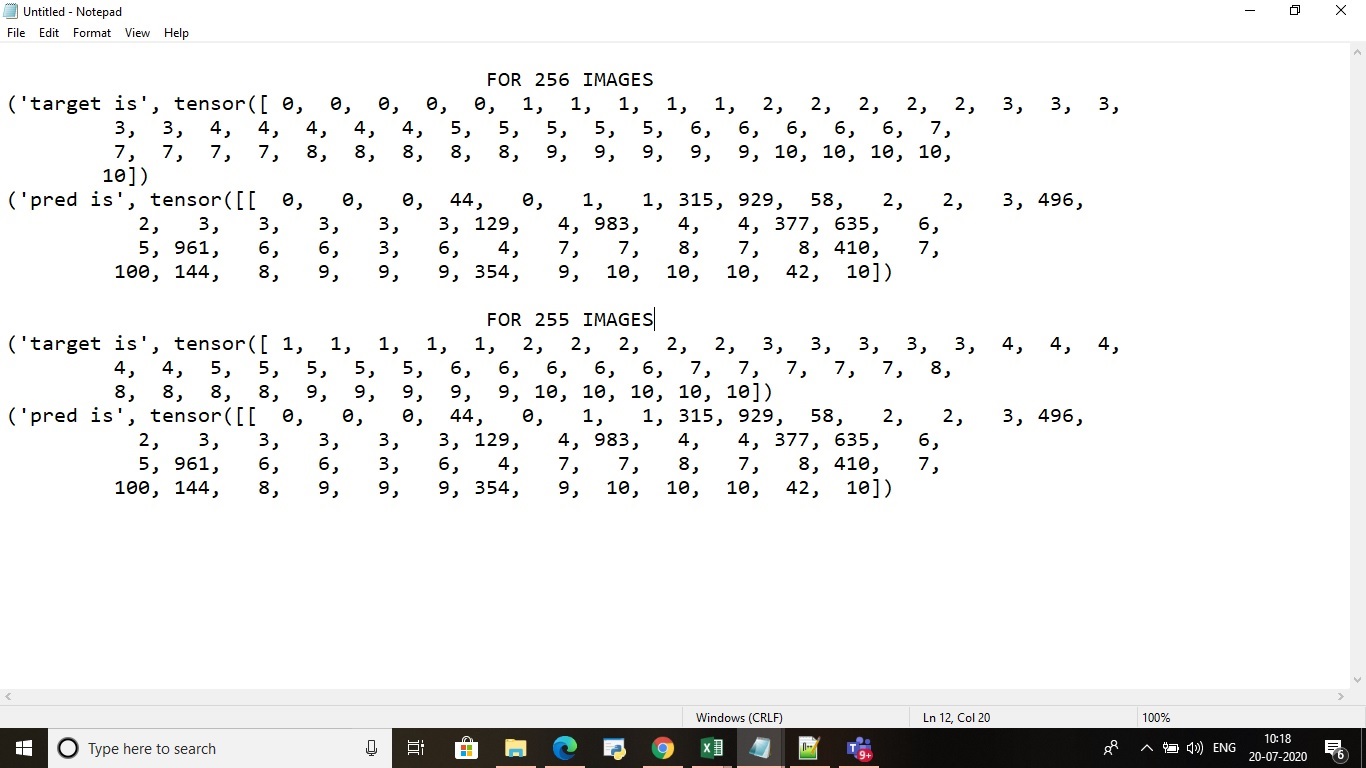
can i know how target is calculated in detail by printing it?(because target is changing for sample<256) have a look into target and prediction of copy of 10 classes
FOR 256 IMAGES
(‘target is’, tensor([ 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3,
3, 3, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 7,
7, 7, 7, 7, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 10, 10, 10, 10,
10,])
(‘pred is’, tensor([[ 0, 0, 0, 44, 0, 1, 1, 315, 929, 58, 2, 2, 3, 496,
2, 3, 3, 3, 3, 3, 129, 4, 983, 4, 4, 377, 635, 6,
5, 961, 6, 6, 3, 6, 4, 7, 7, 8, 7, 8, 410, 7,
100, 144, 8, 9, 9, 9, 354, 9, 10, 10, 10, 42, 10,])
FOR 255 IMAGES
(‘target is’, tensor([ 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4,
4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 8,
8, 8, 8, 8, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10])
(‘pred is’, tensor([[ 0, 0, 0, 44, 0, 1, 1, 315, 929, 58, 2, 2, 3, 496,
2, 3, 3, 3, 3, 3, 129, 4, 983, 4, 4, 377, 635, 6,
5, 961, 6, 6, 3, 6, 4, 7, 7, 8, 7, 8, 410, 7,
100, 144, 8, 9, 9, 9, 354, 9, 10, 10, 10, 42, 10])
I don’t know how the Dataset is defined and what might change the target, so feel free to post the implementation here by wrapping it into three backticks ```, which makes debugging easier. 
this is where my validation dir is defined
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
traindir = os.path.join(args.data, 'train')
valdir = os.path.join(args.data, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[1./255., 1./255., 1./255.])
torchvision.set_image_backend('PIL')
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(valdir, transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
normalize,
])),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)```
this is where my classes,classes_idx ,target are calculated
```def find_classes(dir):
classes = [d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))]
classes.sort()
class_to_idx = {classes[i]: i for i in range(len(classes))}
return classes, class_to_idx
def make_dataset(dir, class_to_idx):
images = []
dir = os.path.expanduser(dir)
for target in sorted(os.listdir(dir)):
d = os.path.join(dir, target)
if not os.path.isdir(d):
continue
for root, _, fnames in sorted(os.walk(d)):
for fname in sorted(fnames):
if is_image_file(fname):
path = os.path.join(root, fname)
item = (path, class_to_idx[target])
images.append(item)```Thanks for the code. Unfortunately I don’t understand it completely.
- How are you changing the number of samples? Are you removing the files manually from certain folders?
- How are
find_classesandmake_datasetused, as it seems you are using thetorchvision.dataset.ImageFolderimplementation? Also, what’s the reason to reimplement them?
Reason is…To do inference with limited samples ,and to check the accuracy of my model i was manipulating with the images(like taking the samples>batch size or less than batch size)
-
so while evaluating my pretrained model for img<batch_size i got very bad precision value
-
I have downloaded the imagenet dataset from the github,each class has 5 images in it ,such like 1000 classes i have
-
To get 256 images i have removed samples from 1000 classes(folder) manually
-
can i know how target is calculated,whether it will get the value during training or on validation?
please have a look into it…
import os
import shutil
import time
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
# import torchvision.transforms as transforms
# import torchvision.datasets as datasets
import model_list
import util
# set the seed
torch.manual_seed(1)
torch.cuda.manual_seed(1)
import sys
import gc
parser = argparse.ArgumentParser(description='PyTorch ImageNet Training')
parser.add_argument('--arch', '-a', metavar='ARCH', default='alexnet',
help='model architecture (default: alexnet)')
parser.add_argument('--data', metavar='DATA_PATH', default='./data/',
help='path to imagenet data (default: ./data/)')
parser.add_argument('--caffe-data', default=False, action='store_true',
help='whether use caffe-data')
parser.add_argument('-j', '--workers', default=8, type=int, metavar='N',
help='number of data loading workers (default: 8)')
parser.add_argument('--epochs', default=100, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N', help='mini-batch size (default: 256)')
parser.add_argument('--lr', '--learning-rate', default=0.001, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--momentum', default=0.90, type=float, metavar='M',
help='momentum')
parser.add_argument('--weight-decay', '--wd', default=1e-5, type=float,
metavar='W', help='weight decay (default: 1e-5)')
parser.add_argument('--print-freq', '-p', default=10, type=int,
metavar='N', help='print frequency (default: 10)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--pretrained', dest='pretrained', action='store_true',
default=False, help='use pre-trained model')
parser.add_argument('--world-size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='gloo', type=str,
help='distributed backend')
best_prec1 = 0
# define global bin_op
bin_op = None
def main():
global args, best_prec1
args = parser.parse_args()
# create model
if args.arch=='alexnet':
model = model_list.alexnet(pretrained=args.pretrained)
input_size = 227
else:
raise Exception('Model not supported yet')
if args.arch.startswith('alexnet') or args.arch.startswith('vgg'):
model.features = torch.nn.DataParallel(model.features)
model.cuda()
else:
model = torch.nn.DataParallel(model).cuda()
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), args.lr,
weight_decay=args.weight_decay)
for m in model.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
c = float(m.weight.data[0].nelement())
m.weight.data = m.weight.data.normal_(0, 2.0/c)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data = m.weight.data.zero_().add(1.0)
m.bias.data = m.bias.data.zero_()
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
del checkpoint
else:
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
# Data loading code
if args.caffe_data:
print('==> Using Caffe Dataset')
cwd = os.getcwd()
sys.path.append(cwd+'/../')
import datasets as datasets
import datasets.transforms as transforms
if not os.path.exists(args.data+'/imagenet_mean.binaryproto'):
print("==> Data directory"+args.data+"does not exits")
print("==> Please specify the correct data path by")
print("==> --data <DATA_PATH>")
return
normalize = transforms.Normalize(
meanfile=args.data+'/imagenet_mean.binaryproto')
train_dataset = datasets.ImageFolder(
args.data,
transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
transforms.RandomSizedCrop(input_size),
]),
Train=True)
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True, sampler=train_sampler)
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(args.data, transforms.Compose([
transforms.ToTensor(),
normalize,
transforms.CenterCrop(input_size),
]),
Train=False),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
else:
print('==> Using Pytorch Dataset')
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
traindir = os.path.join(args.data, 'train')
valdir = os.path.join(args.data, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[1./255., 1./255., 1./255.])
torchvision.set_image_backend('accimage')
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(valdir, transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
normalize,
])),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
print model
# define the binarization operator
global bin_op
bin_op = util.BinOp(model)
if args.evaluate:
validate(val_loader, model, criterion)
return
for epoch in range(args.start_epoch, args.epochs):
adjust_learning_rate(optimizer, epoch)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch)
# evaluate on validation set
prec1 = validate(val_loader, model, criterion)
# remember best prec@1 and save checkpoint
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer' : optimizer.state_dict(),
}, is_best)
def train(train_loader, model, criterion, optimizer, epoch):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
target = target.cuda(async=True)
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# process the weights including binarization
bin_op.binarization()
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.data.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
# restore weights
bin_op.restore()
bin_op.updateBinaryGradWeight()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
gc.collect()
def validate(val_loader, model, criterion):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
bin_op.binarization()
for i, (input, target) in enumerate(val_loader):
target = target.cuda(async=True)
with torch.no_grad():
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.data.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1, top5=top5))
bin_op.restore()
print(' * Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(top1=top1, top5=top5))
return top1.avg
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best.pth.tar')
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
print 'Learning rate:', lr
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == '__main__':
main()```problem is, if I delete the samples manually,in my dataset directory i have .ipynb_checkpoints so my precision was bad results in
.ipynb_checkpoints
[‘.ipynb_checkpoints’, ‘n01440764’]
- can i know how to delete this ,or to change this behaviour permanently?
You might need to change the working directory of your notebook (or the directory where the checkpoints are created).
These additional folders would explain the class index shift.
Ya, this was creating the index shift in my target
Thanks for your reply ![]()