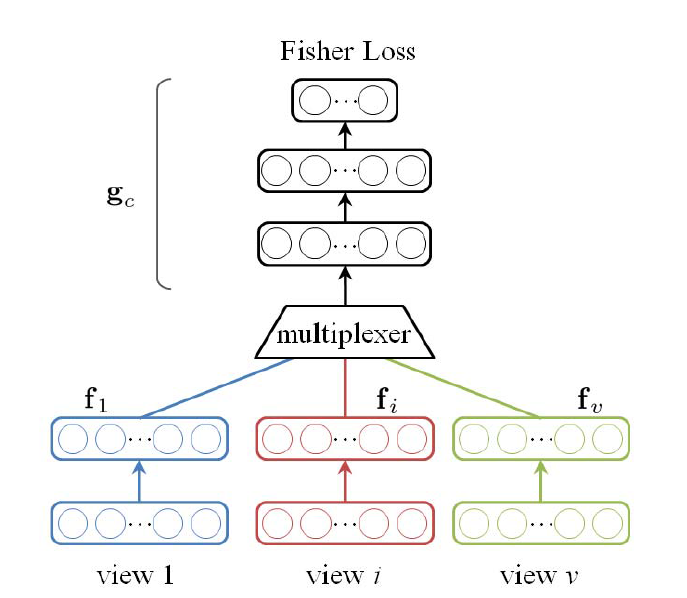
As shown in the following figure, the framework consists of several view-specific subnets (f1, f2, … , fv) and a multiplex net. (gc).
In the training phase, the loss function needs all the output of ((f1, f2, … , fn). Of course, we have training data for parallel inputting.
However, when it comes to test phase, only one view-specific subnet (ft) is activated for input.![]()
Should I build the f1, f2, … , fv within the gc? Or build them alone, and finally combine the parameters in the training phase?
Thank you!