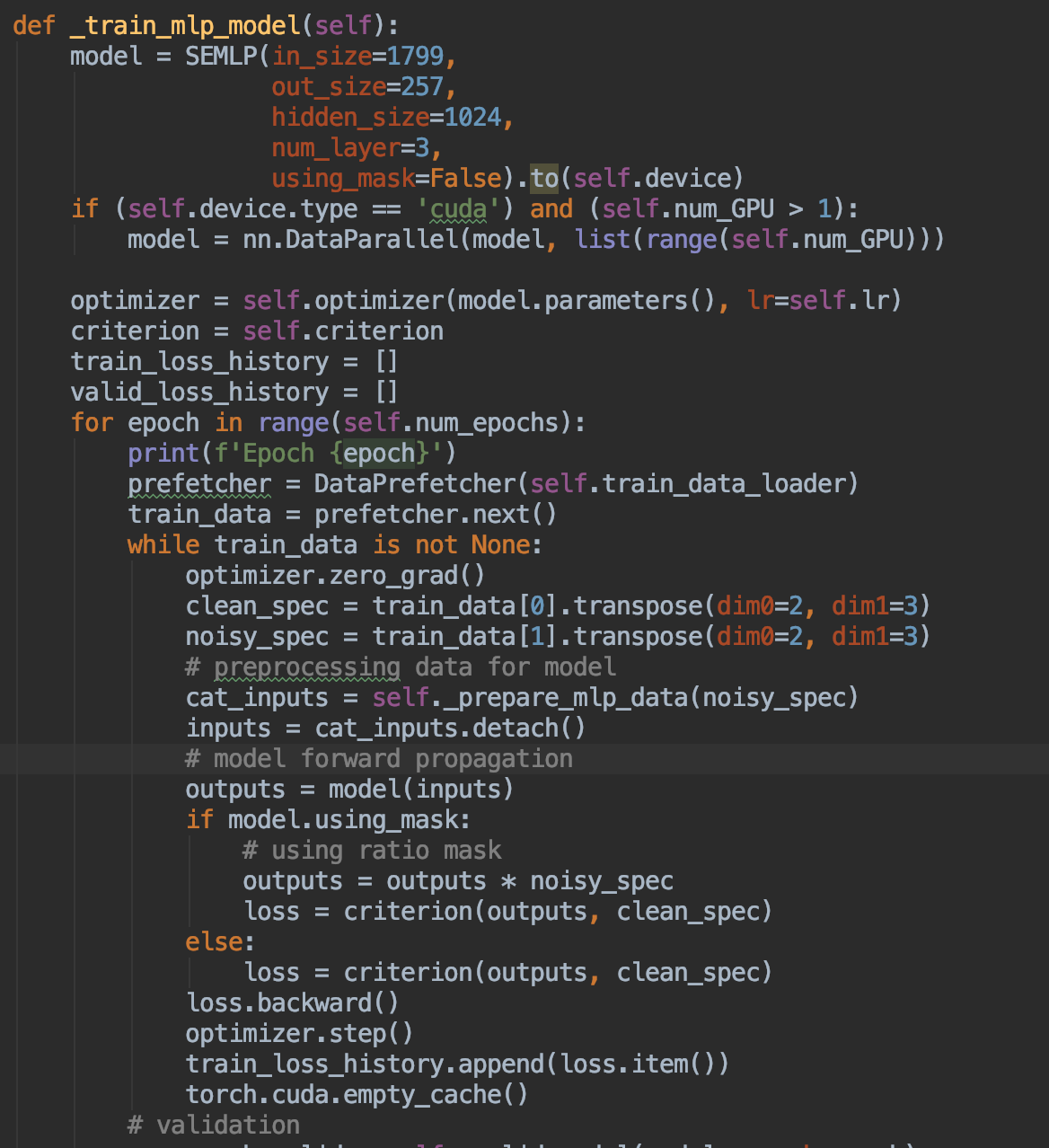
Many thanks! Actually, I’m think there is a bottle neck of my training process and I’m trying to find it out. I am training a 3-layers MLP model but the training is irrationally slow.
Though I did a preprocessing of data in the training loop, I think it won’t influence the training time too much, because the preprocessing should be accelerated by CUDA.
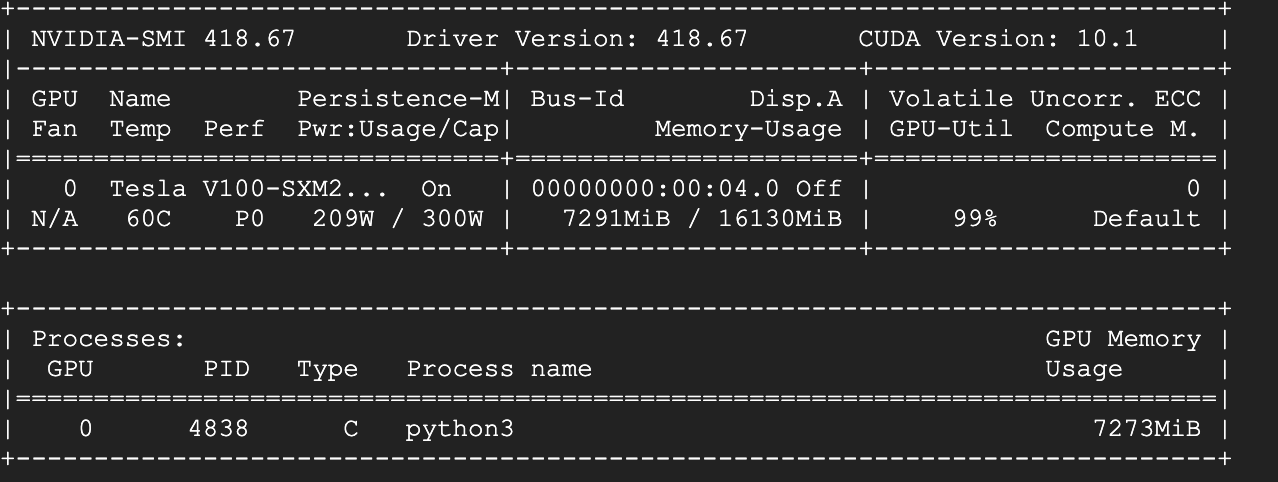
The most weird thing is the training seems be slower epoch by epoch, though I use a torch.cuda.empty_cache, it doesn’t help much.
A preload is also implement, so the GPU is not starving.