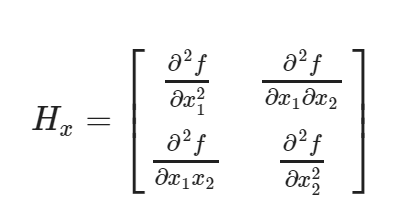I’d like to compute the second derivative of the loss w.r.t. a model (nn.module), but I cannot do this:
params = torch.cat([p.flatten() for p in policy.parameters()], dim=0)
for i in range(200):
y = get_expected_return(policy)
grad = torch.autograd.grad(y, params, create_graph=True)[0]
with torch.no_grad():
params += grad
So, I need to do this:
for i in range(200):
y = get_expected_return(policy)
grad = torch.autograd.grad(y, policy.parameters(), create_graph=True)
with torch.no_grad():
for p, g in zip(policy.parameters(), grad):
p += g
But, the first solution is required for the second derivative. So, anybody knows how to make the first code work?
Thanks for you answer, sorry for my late response (did not get a notification).
The second solution works, but now how do I compute the second derivative?
for i in range(200):
y = get_expected_return(policy)
grad = torch.autograd.grad(y, policy.parameters(), create_graph=True)
for gvec, (name,theta) in zip(grad, policy.named_parameters()):
gvec=gvec.flatten()
H = [torch.autograd.grad(g, theta, create_graph=True)[0].unsqueeze(0) for g in gvec]
Is this correct?
Consider two parameter sets, x1 and x2. The H should be computed by:
In my code, where am I computing right upper and left lower elements?