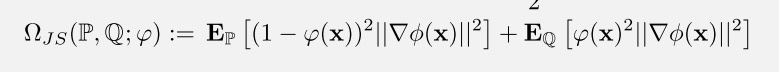To compute gradients (which implies that the output of the function is scalar),
The outputs you pass to autograd.grad should be either of the following:
A Variable wrapping a Tensor of size (1,) (something like a scalar)
An arbitrary tuple of Variables. In this case, you should specify a grad_output= for autograd.grad that has the same shape as the arbitrary tuple of Variables.
I was also looking for a solution to the problem of JS regulation for PyTorch. I was inspired by the regularization method of the WGAN-GP. Here is the solution that I propose to you.
def discriminator_regularizer(critic, D1_args, D2_args):
'''
JS-Regularizer
A Methode that regularize the gradient when discriminate real and fake.
This methode was proposed to deal with the problem of the choice of the
careful choice of architecture, paremeter intializaton and selction
of hyperparameters.
GAN is highly sensitive to the choice of the latters.
According to "Stabilizing Training of Generative Adversarial Networks
through Regularization", Roth and al., This fragility is due to the mismathch or
non-overlapping support between the model distribution and the data distribution.
:param critic : Discriminator network,
:param D1_args : real value
:param D2_args : fake value
'''
BATCH_SIZE, *others = D1_args.shape
DEVICE = D1_args.device
D1_args = Variable(D1_args, requires_grad=True)
D2_args = Variable(D2_args, requires_grad=True)
D1_logits, D2_logits = critic(D1_args), critic(D2_args)
D1, D2 = torch.sigmoid(D1_logits), torch.sigmoid(D2_logits)
grad_D1_logits = torch.autograd.grad(outputs=D1_logits, inputs=D1_args,
create_graph=True, retain_graph=True,
grad_outputs=torch.ones(D1_logits.size()).to(DEVICE))[0]
grad_D2_logits = torch.autograd.grad(outputs=D2_logits, inputs=D2_args,
create_graph=True, retain_graph=True,
grad_outputs=torch.ones(D2_logits.size()).to(DEVICE))[0]
grad_D1_logits_norm = torch.norm(torch.reshape(grad_D1_logits,(BATCH_SIZE,-1)),
dim=-1, keepdim=True)
grad_D2_logits_norm = torch.norm(torch.reshape(grad_D2_logits,(BATCH_SIZE,-1)),
dim=-1, keepdim=True)
assert grad_D1_logits_norm.shape == D1.shape
assert grad_D2_logits_norm.shape == D2.shape
reg_D1 = torch.multiply(torch.square(1. - D1), torch.square(grad_D1_logits_norm))
reg_D2 = torch.multiply(torch.square(D2), torch.square(grad_D2_logits_norm))
discriminator_regularizer = torch.sum(reg_D1 + reg_D2).mean()
return discriminator_regularizer