Hello, guys. Recently, i have been engaged in rewriting the tensorflow implement of miyosuda/unreal of paper Reinforcement learning with unsupervised auxiliary tasks. using pytorch. In thise paper, it describes three auxiliary tasks which used the shared weights of Conv and LSTM layers created by base A3C.
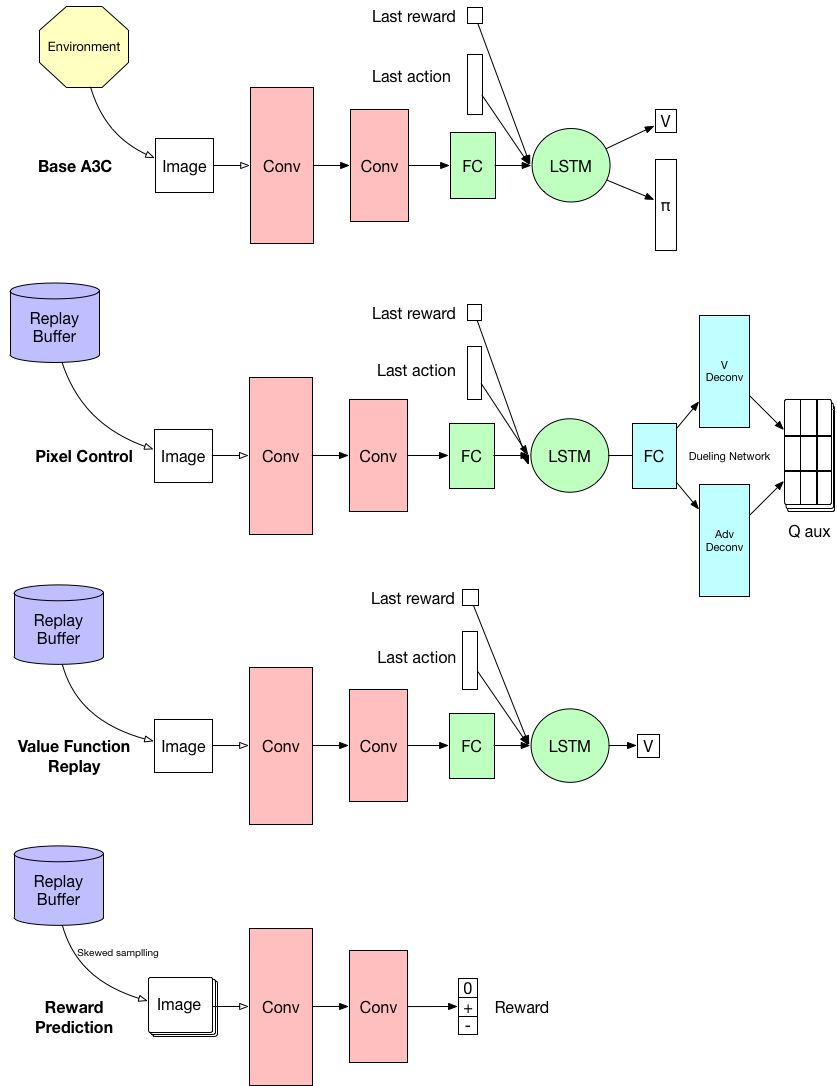
forward method in order to decide which task to be the output. Here is my implement:
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from utils import norm_col_init, weights_init, normalized_columns_initializer
from torch.nn.init import uniform_
import numpy as np
class UNREAL(torch.nn.Module):
def __init__(self, in_channels,
action_size,
enable_pixel_control=True,
enable_value_replay=True,
enable_reward_prediction=True):
super(UNREAL, self).__init__()
self._action_size = action_size
self._enable_pixel_control = enable_pixel_control
self._enable_value_replay = enable_value_replay
self._enable_reward_prediction = enable_reward_prediction
# A3C base
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=16, kernel_size=8, stride=4) # RGB -> 16
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=4, stride=2) # 16->32
# FC
self.linear_fc = nn.Linear(in_features=2592, out_features=256)
# self.lstm = nn.LSTMCell(256 + self._action_size + 1, 256) # conv + action_size + reward(1)
self.lstm = nn.LSTM(256 + self._action_size + 1, 256, 1, batch_first=True) # input, hidden, layer=1
# Actor-Critic
self.critic_linear = nn.Linear(256, 1)
self.actor_linear = nn.Linear(256, self._action_size)
# softmax
self.softmax = nn.Softmax(1)
#
self._conv_init(self.conv1)
self._conv_init(self.conv2)
self._fc_init(self.linear_fc)
# aux task
if self._enable_pixel_control:
self._create_pixel_control()
self._fc_init(self.pc_linear)
self._conv_init(self.pc_deconv_a)
self._conv_init(self.pc_deconv_v)
if self._enable_value_replay:
pass # value replay
if self._enable_reward_prediction:
self._create_reward_prediction()
self._fc_init(self.rp_linear)
def _conv_init(self, conv: nn.Conv2d):
d = 1.0 / np.sqrt(conv.in_channels * conv.kernel_size[0] * conv.kernel_size[1])
uniform_(conv.weight.data, a=-d, b=d)
uniform_(conv.bias.data, a=-d, b=d)
def _fc_init(self, linear: nn.Linear):
d = 1.0 / np.sqrt(linear.in_features)
uniform_(linear.weight.data, a=-d, b=d)
uniform_(linear.bias.data, a=-d, b=d)
def _create_pixel_control(self):
self.pc_linear = nn.Linear(256, 9 * 9 * 32)
self.pc_deconv_v = nn.ConvTranspose2d(in_channels=32, out_channels=1, kernel_size=4, stride=2)
self.pc_deconv_a = nn.ConvTranspose2d(in_channels=32, out_channels=self._action_size, stride=2, kernel_size=4)
def _create_reward_prediction(self):
self.rp_linear = nn.Linear(9 * 9 * 32 * 3, 3)
def forward(self, task_type, states, hx=None, cx=None, last_action_rewards=None):
x = F.relu(self.conv1(states))
x = F.relu(self.conv2(x))
# rp
if task_type == 'rp':
x = x.view(1, 9 * 9 * 32 * 3) # state: [batch, h, w, 3]
x = self.rp_linear(x)
return x # logits
x = x.view(-1, 2592)
# unroll
x = F.relu(self.linear_fc(x)) # unroll_step, 256
# last_action, last_reward
x = torch.cat([x, last_action_rewards], dim=1)
# LSTM flatten
x = x.view(-1, 1, 256 + self._action_size + 1) # (unroll_step, 1, 256 + action_size + 1),
x, (hx, cx) = self.lstm(x, (hx, cx)) # (batch, seq, dim)
x = x.squeeze(dim=1)
if task_type == 'a3c':
return self.critic_linear(x), self.actor_linear(x), hx, cx # crtic: [batch,1], actor: [batch,action_size], hx, cx
elif task_type == 'pc':
x = F.relu(self.pc_linear(x))
x = torch.reshape(x, [-1, 32, 9, 9]) # NCHW
pc_deconv_v = F.relu(self.pc_deconv_v(x))
pc_deconv_a = F.relu(self.pc_deconv_a(x))
pc_deconv_a_mean = torch.mean(pc_deconv_a, dim=1, keepdim=True)
# pc_q
pc_q = pc_deconv_v + pc_deconv_a - pc_deconv_a_mean
# max q
pc_q_max = torch.max(pc_q, dim=1, keepdim=False)[0]
return pc_q, pc_q_max, hx, cx
elif task_type == 'vr':
return self.critic_linear(x) # a3c
Environment
- pytorch 1.1
- python 3.6.5
- enable pytorch built-in multiprocess, 8 agents
- shared model is hold in GPU, local network in memory
But when i run the code, i find it is harder for the network to convergence. May be I made mistakes? Thanks 