Is there any solution for this ? We work on a shared server, and sometimes I need to free gpu memory for other users without killing the whole kernel. Your code indeed frees the reserved memory (torch.cuda.memory_reserved() returns 0), but nvidia-smi still shows that my kernel is occupying the memory.
PS : I use jupyter-lab, that’s why sometimes I still need the kernel after that my model has finished training.
nvidia-smi will show the allocated memory by all processes. If you are only running PyTorch then the CUDA context would still use device memory (~1GB depending on the GPU etc.) and cannot be released without stopping the Python kernel.
Thank you for your reply. I am afraid that nvidia-smi shows all the GPU memory that is occupied by my notebook. For instance, if I train a model that needs 15 GB of GPU memory, and that I free the space using torch (by following the procedure in your code) , the torch.cuda.memory_reserved() will return 0, but nvidia-smi would still show 15GB.
nvidia-smi indeed shows all allocated memory, so if it’s still showing 15GB then some applications are still using it. If you are not seeing any memory usage (either allocated or in the cache) via torch.cuda.memory_summary(), another application (or python kernel) would use the device memory.
Any solution here? Memory is not freed, see minimal example:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6"
import torch
from transformers import LlamaForCausalLM
model = LlamaForCausalLM.from_pretrained(
pretrained_model_name_or_path='decapoda-research/llama-7b-hf',
load_in_8bit=True,
device_map={'': 0},
)
del model
torch.cuda.empty_cache()
print('breakpoint here - is memory freed?')
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6"
import torch
from transformers import LlamaForCausalLM
model = LlamaForCausalLM.from_pretrained(
pretrained_model_name_or_path='decapoda-research/llama-7b-hf',
load_in_8bit=True,
device_map={'': 0},
)
del model
import gc
gc.collect()
torch.cuda.empty_cache()
print('breakpoint here - is memory freed?')
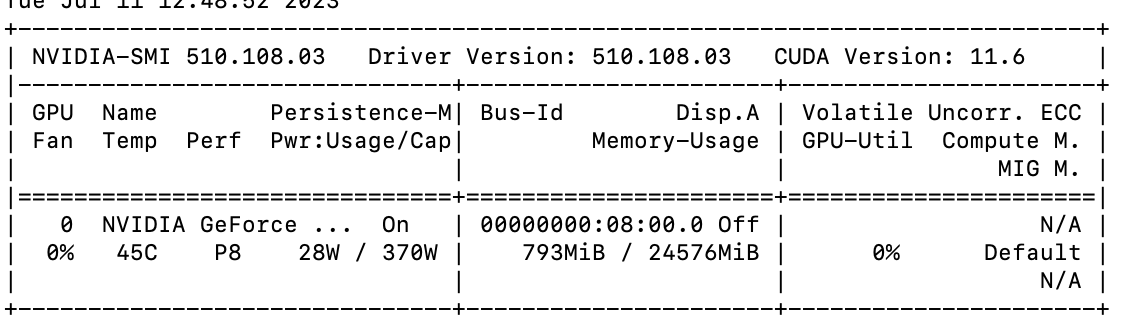
As soon as i load the model, the memory usage goes to 793MB, which I believe is memory occupied by CUDA context, as nothing is passed to the model at this stage. And also even if I delete the two models loaded (model and feature segmentor) and clear the cache with torch.cuda.empty_cache() to check the memory status, the memory usage stays the same 793MB.
Then at the next step, when I execute the following code:
with torch.no_grad():
model.eval()
avg_train_dice = []
for img in range(len(dataset_val)): # looping over all 3D files
train_samples, gt_samples, voxel = dataset_val[img] # Get the ith image, label, and voxel
stronger_predictions = []
predictions = []
for slice_id, img_slice in enumerate(train_samples): # looping over single img
img_slice = img_slice.unsqueeze(0)
img_slice = img_slice.to(device)
stronger_pred = model(img_slice)
stronger_pred = stronger_pred.detach().cpu()
stronger_predictions.append(stronger_pred.squeeze())
del img_slice
del stronger_pred
torch.cuda.empty_cache()
stronger_preds = torch.stack(stronger_predictions, dim= 0)
stronger_predictions.clear()
stronger_preds_prob = torch.sigmoid(stronger_preds)
if n_channels_out == 1:
train_dice = sdice(gt_samples.squeeze().numpy()>0,
stronger_preds_prob.numpy() > 0.5,
voxel[img])
else:
train_dice = dice_score(torch.argmax(stronger_preds_prob, dim=1) ,torch.argmax(gt_samples, dim=1), n_outputs=n_channels_out)
avg_train_dice.append(train_dice)
avg_train_dice = np.mean(avg_train_dice)
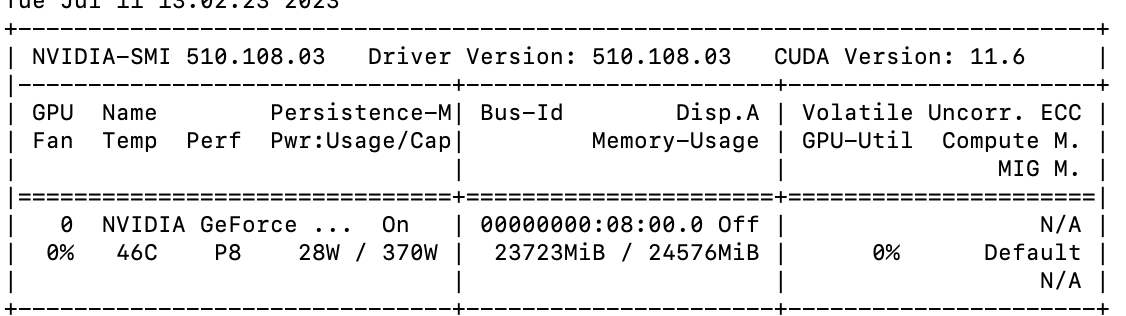
After this step completes, the memory usagreaches to 23723MB, but I was not calculating graidents in this step with torch.no_grad() specified, and deleted the tensors and cleared the cache too as can be seen in the code. I am not able to understand that why it is happening, since their is no gradient calculation, the data has been loaded and un loaded (confirmed by GPU utilization %), but still memory usage goes from the intial 793MB to 23723MB.
So, the memory is almost full and as soon as I go to my next step the following code:
for epoch in range(1, num_epochs + 1):
model.train()
train_loss_total = 0.0
num_steps = 0
for i, batch in enumerate(train_loader):
input_samples, gt_samples, _ = batch
var_input = input_samples.cuda(device)
try:
stronger_preds = model(var_input)
except:
embed()
if level == 0:
layer_activations = model.init_path(var_input)
preds = features_segmenter(layer_activations)
del var_input
# embed()
else: # level = 1
layer_activations_0 = model.init_path(var_input)
layer_activations_1 = model.down1(layer_activations_0)
logits_ = features_segmenter(layer_activations_1)
preds = F.interpolate(logits_, scale_factor=2, mode='bilinear')
if n_channels_out == 1:
stronger_preds_prob = torch.sigmoid(stronger_preds)
loss = weighted_cross_entropy_with_logits(preds, stronger_preds_prob)
# loss = weighted_cross_entropy_with_logits(preds, stronger_preds)
else:
# loss = -torch.mean(F.log_softmax(preds, dim=1)*F.softmax(stronger_preds, dim=1))
loss = CE_loss(preds, torch.argmax(stronger_preds, dim=1))
train_loss_total += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
num_steps += 1
train_loss_total_avg = train_loss_total / num_steps
num_steps = 0
print('avg train loss', train_loss_total_avg)
The above code breaks after 1st iteration and generates the following error as no memory is left. OutOfMemoryError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 23.70 GiB total capacity; 21.92 GiB already allocated; 33.00 MiB free; 22.29 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
The above simple tensor deletion seems fine to me however, when there is gets a little more complex, I found GPU memory are not released. The code follows.
import torch
import os
hidden_size = 1000
def print_cuda_mem():
print(f"allocated: {torch.cuda.memory_allocated() / 1e6}MB, max: {torch.cuda.max_memory_allocated() / 1e6}MB, reserved: {torch.cuda.memory_reserved() / 1e6}MB")
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(hidden_size, hidden_size)
def forward(self, x):
return self.linear(x)
def test_mem():
print_cuda_mem()
rand_input = torch.rand(hidden_size, hidden_size, device='cuda')
print_cuda_mem()
s1 = torch.cuda.memory_snapshot()
model = Model().cuda()
s2 = torch.cuda.memory_snapshot()
print_cuda_mem()
with torch.no_grad():
y = model(rand_input).sum().detach().cpu()
print(y)
s3 = torch.cuda.memory_snapshot()
print_cuda_mem()
del rand_input
del model
del y
s4 = torch.cuda.memory_snapshot()
torch.cuda.empty_cache()
import gc
gc.collect()
s5 = torch.cuda.memory_snapshot()
print_cuda_mem()
if __name__ == '__main__':
test_mem()
import gc
gc.collect()
s6 = torch.cuda.memory_snapshot()
print_cuda_mem()
Even with manual gc and with torch.no_grad(), I found that there is still active memory usage (allocated: 8.970752MB) after s4 (s4, s5 and s6). I also looked deeper into the snapshot and confirmed that the active memory is created between s2 and s3, the model forwarding.
Any ideas and thanks! PyTorch version: 2.1.1+cu118
The remaining memory will be used by the cuBLAS workspace and you can free it via:
torch._C._cuda_clearCublasWorkspaces()
print('after clearing the cuBLAS workspace', torch.cuda.memory_allocated())
after clearing the cuBLAS workspace 0
@ptrblck Thanks for the answer! This memory retained by cuBLAS is not due to “alive” tensors right (they are garbage collected after del) but for optimization reasons?
It should be noted that if there is no forward pass, i.e.:
import torch
print('on start', torch.cuda.memory_allocated())
x = torch.randn(32, 32, device='cuda')
model = torch.nn.Linear(32, 128, device='cuda')
# model(x)
print('before deleting', torch.cuda.memory_allocated())
del x, model
print('after deleting', torch.cuda.memory_allocated())
torch.cuda.empty_cache()
print('after empty cache', torch.cuda.memory_allocated())
the memory is freed without needing to call torch._C._cuda_clearCublasWorkspaces().
Technically, the workspace was allocated through PyTorch (which is also why we can delete it), so an internal tensor is alive. However, from your script’s perspective you are correct and no explicitly created tensor is alive anymore after deleting it.
Yes, the workspace allows cuBLAS to select more algorithms and you can think about it as a buffer.
Is this internal tensor related to autograd? Because as shown in the example, without the forward pass, everything works as “expected” (from the script’s perspective).
Meet the same problem here when I was trying to delete weights of a Linear module. I delete the weight parameters and call gc, empty_cache, and synchronize but none of them address the issue. I hold the same point that autograd might be the reason. I address this issue by adding “with torch.no_grad()” as mentioned in the earlier replies.
Not sure to understand: did using with torch.no_grad() fix your issue?
Also, could it be that you just iterate over the model’s parameters and call del param for each of them? This will merely delete the reference you just created. The params will still be referenced by the model, and the memory will thus not be freed by the garbage collector.
Can you share the code of how you delete these weights?
Here’s an example of my codes. Before adding no_grad, In this way, the weight is for sure being deleted from model (verified) but it is still kept on GPU. But after adding no_grad, the memory is recollected successfully.
I think in my for loop, module is the reference created, since I delete “module.weight”, it should delete the weight for the original model (and I think it did because the model I obtained after removing indeed have no weight).
with torch.no_grad():
for name, module in tqdm(model.named_modules()):
if name in targets:
if 'weight' in module._parameters:
del module._parameters['weight']
torch.cuda.empty_cache()
torch.cuda.synchronize(device)