Hi, almighty guys ![]() .
.
I’m a beginner in digital audio signal processing. And I met some questions during reading a paper.
- When I get the filter banks outputs from a 10s audio segment, should I send all of them into the model or just several frames?
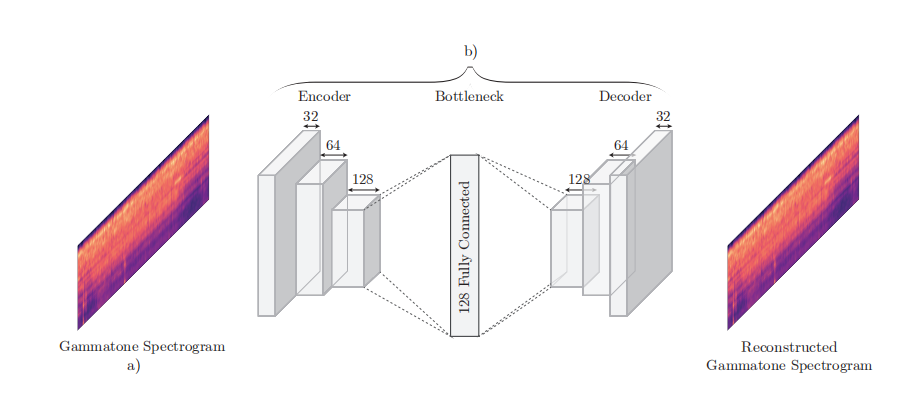
- I’m a little confused about the model architecture in the paper. How does the dense layer connect with the encoder and decoder. Does it convert a Bx1x1x128 tensor to a Bx128xhxw tensor?