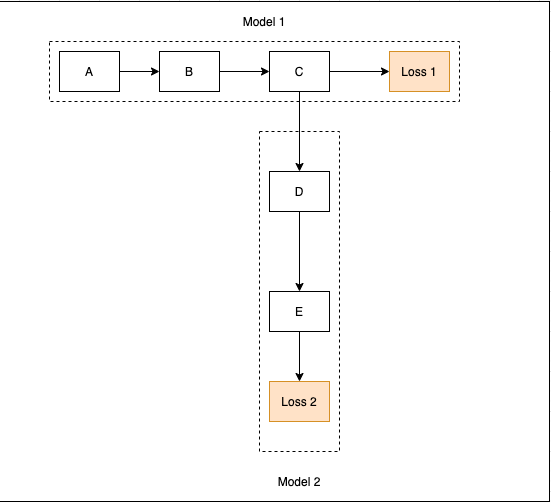
I have this model depicted in the figure. Model 1 and model 2 used to be two disjoint models such that they worked in a pipeline that we first train model 1 till convergence and feed the preprocessed outputs to model 2 as inputs. I am now training them end to end and I am struggling with how to integrate these two losses instead of just using loss 2. Other quesiton is, can I use two different optimizers for each of their parameters.
Should I do loss1.backward() first to update the gradients for the first model and then do loss2.backward() which will update the gradients for both model 1 and model 2 parameters. Do you think this is a good idea where gradients can be updated from both losses with a controlled learning rate so that I can force model 1 to learn more from loss1 than from loss2?
Another idea that came to my mind is to sum both loss1 and loss2 (let’s call it loss3) and backpropagate. I have the initial idea that loss3 will only backpropagate loss2 until it reaches c and then backpropagated the weighted sum. Is that right?
Any ideas or references to the literature will be appreciated.