Hey, there!
I have some problem with my CNN model.
It takes image at input, then pushes image forward to 2 submodels - midlevel feature extractor and global feature extractor. Some image for understanding provided below: The output shape of midlevel feature extractor is (64,28,28), the size of global feature extractor verctor is 64.
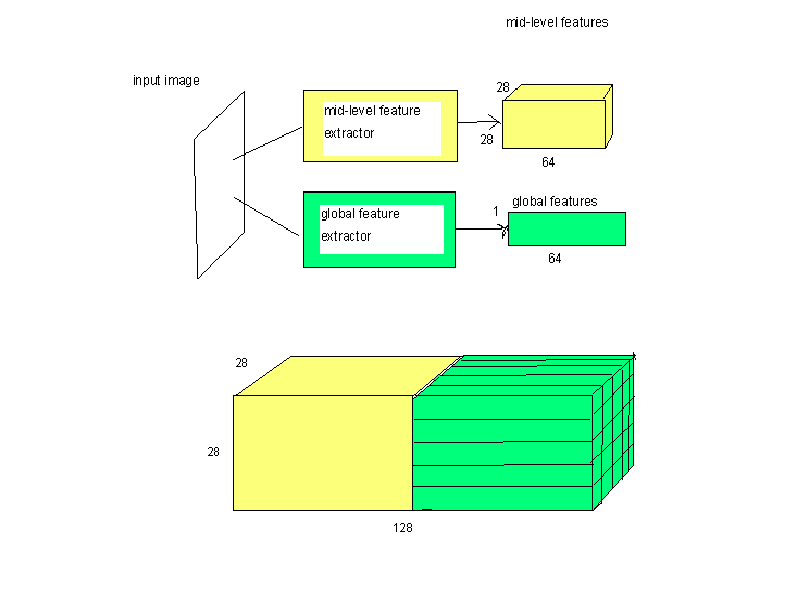
I want to merge these ouputs in channel dimension per pixel, so the total output would be the size of (128, 28, 28). Another image is provided below.
Can someone advice what it the best way to do it in pytorch?
I tried to use expand method:
def forward(self, x):
x1 = self.midlevel_feature_extractor(x) #midlevel features
x2 = self.global_feature_extractor(x) #global features
#expanding
x2 = x2.expand((x1.size()[2], x1.size()[3], x1.size()[0], x1.size()[1])).permute((2,3,0,1))
#concat
concatenated_features = torch.cat((x1, x2), dim=1)
...
But it result to error during training (I think problem is in wrong concatenating)
So, any ideas, guys?