Hi, folks. It seems that most of the deep neural networks, which can be implemented by PyTorch, must have an explicit feedforwad process to compute each layer’s hidden representation.
What if there is no such an explicit feedforwad process? For example, in the Deconvolutional Networks, the representation of each layer is computed by performing an iterative minimization process like sparse coding. A formal description of this problem is:
At the first layer, we view x as the input, y^1 as the hidden representaion, and W^1 as the generative parameter. We minimize the following loss function to alternatively update y^1 and W^1:
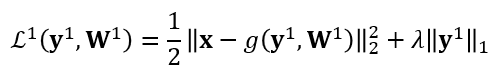
Similarly, at the second layer, we minimize the following loss function to alternatively update y^2 and W^2:
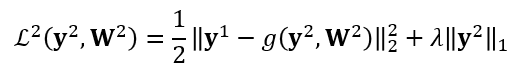
At the third layer…
So how can we build and train this network with PyTorch?
Thanks in advance for any suggestions and comments.