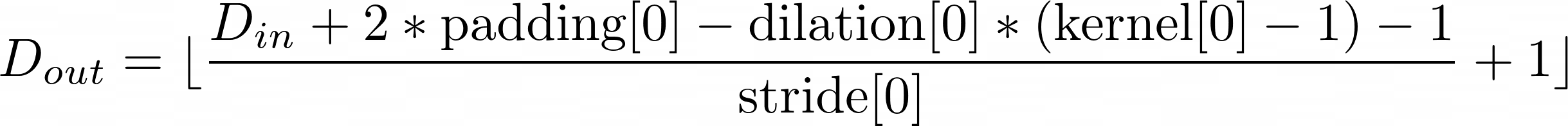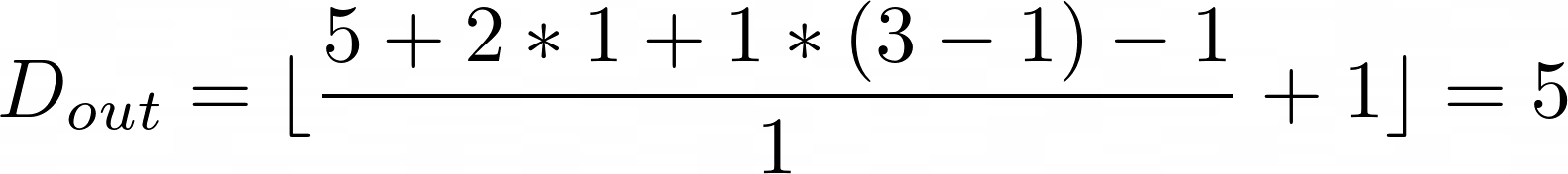Hello,
I am trying to use a conv3d layer to for images with multiple frames, but I would like the output to have the same depth before and after the layer (ie: D == D_out like this.
Right now my input shape is:
(6, 5, 3, 78, 136)
This is with a batch size of 6, and a depth of 5 (ie: D = 5)
The conv3d block is initialized as:
torch.nn.Conv3d(3, 64, kernel_size=3, padding=1, stride=(1, 2, 2))
When I run this, the error I get is:
RuntimeError: Given groups=1, weight of size [64, 2, 3, 3, 3], expected input[6, 5, 2, 78, 136] to have 2 channels, but got 5 channels instead
I guess what I want is weights of size [64, 5, 3, 3, 3] to have D = D_out. How can I accomplish this?