In order to avoid numerical instability, we should use a variable change:
eta = log(sigma)
The new variable eta can be defined within (-oo, +oo).
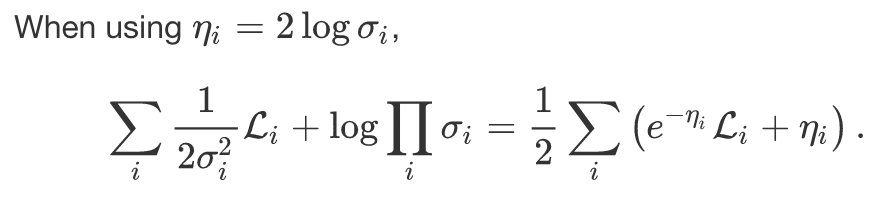
Sample code:
import torch
import torch.nn as nn
import torch.optim as optim
class MultiTaskLoss(nn.Module):
def __init__(self, model, loss_fn, eta):
super(MultiTaskLoss, self).__init__()
self.model = model
self.loss_fn = loss_fn
self.eta = nn.Parameter(torch.Tensor(eta))
def forward(self, input, targets):
outputs = self.model(input)
loss = [l(o,y).sum() for l, o, y in zip(self.loss_fn, outputs, targets)]
total_loss = torch.Tensor(loss) * torch.exp(-self.eta) + self.eta
return loss, total_loss.sum() # omit 1/2
class MultiTaskModel(nn.Module):
def __init__(self):
super(MultiTaskModel, self).__init__()
self.f1 = nn.Linear(5, 1, bias=False)
self.f2 = nn.Linear(5, 1, bias=False)
def forward(self, input):
outputs = [self.f1(x).squeeze(), self.f2(x).squeeze()]
return outputs
mtl = MultiTaskLoss(model=MultiTaskModel(),
loss_fn=[nn.MSELoss(), nn.MSELoss()],
eta=[2.0, 1.0])
print(list(mtl.parameters()))
x = torch.randn(3, 5)
y1 = torch.randn(3)
y2 = torch.randn(3)
optimizer = optim.SGD(mtl.parameters(), lr=0.1)
optimizer.zero_grad()
loss, total_loss = mtl(x, [y1, y2])
print(loss, total_loss)
total_loss.backward()
optimizer.step()
Output:
[Parameter containing:
tensor([2., 1.], requires_grad=True), Parameter containing:
tensor([[-0.0387, 0.3287, 0.2549, 0.3336, 0.0195]], requires_grad=True), Parameter containing:
tensor([[0.2908, 0.2801, 0.1108, 0.4235, 0.0308]], requires_grad=True)]
[tensor(3.3697, grad_fn=<SumBackward0>), tensor(2.1123, grad_fn=<SumBackward0>)] tensor(4.2331, grad_fn=<SumBackward0>)