So I am currently playing around with Super-Resolution Generative Adversarial Network and gray-scale images. I am using the PyTorch implementation here. Since VGG network expects 3 channels as input I did the following to make it work:
target_images = target_images.repeat(1, 3, 1,1)
out_images = out_images.repeat(1, 3, 1,1)
However I noticed that the discriminators loss quickly went to 0 and the score of Discriminator and Generator did not oscillate around 0.5 as expected.

However when I trained the network with color images I got the following losses which was what I would expect:
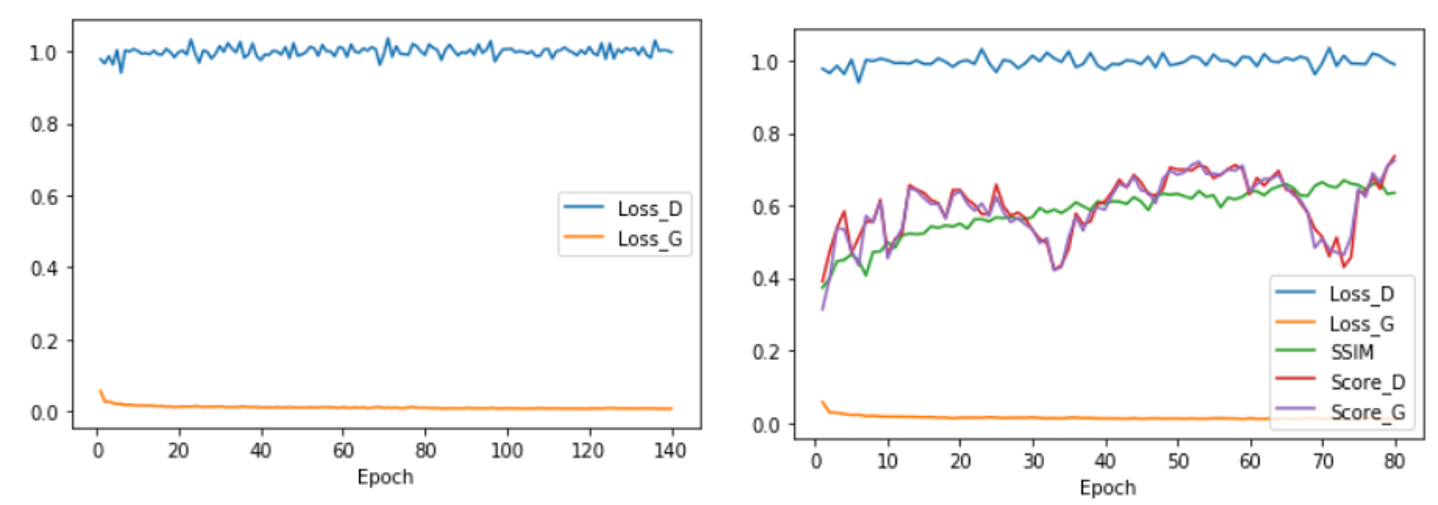
I tried multiple things to fix this and none of them worked such as: training generator more often, training discriminator more often and add more layers to both discriminator and generator. The newest Idea was to only train discriminator if the loss was above a specific value. Is this a bad idea? I tried this the following way:
# Calculate gradients for D in backward pass
if d_loss >D_LOSS_MIN:
d_loss.backward(retain_graph=True)
# causes the optimizer to take a step based on the gradients of the parameters.
if d_loss >D_LOSS_MIN:
optimizerD.step()
Is this the correct way of not updating the discriminator by only doing backward and step if the discriminators loss is above some value? Or am I missing something? When I try with D_LOSS_MIN = 0.9 the discriminators loss never goes above 0.9. So as far as I understand the discriminator never get updated.
And do any of you have some suggestions of how to improve it?
Thanks!