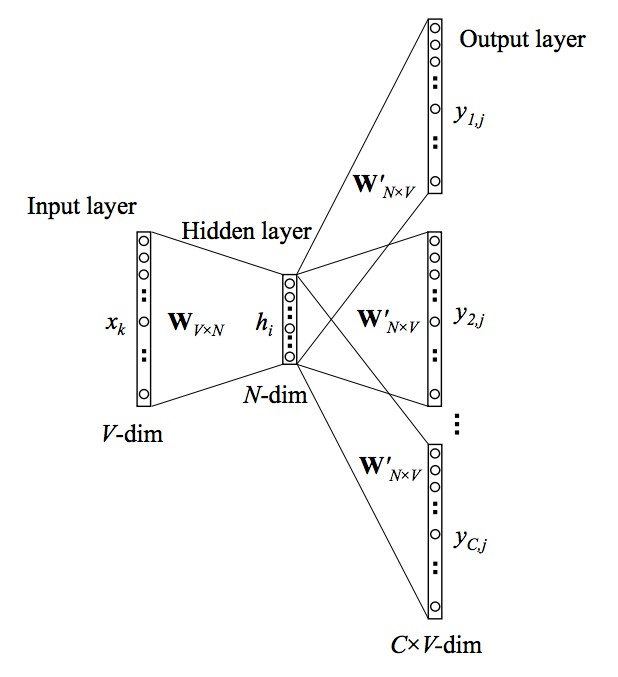
I think I find a way to solve this problem.
First, here are my code of Model and Training.
The code of Model
class SkipGram(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(SkipGram, self).__init__()
self.vocab_size = vocab_size
self.context_size = context_size
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(embedding_dim, 128)
self.linear2 = nn.Linear(128, vocab_size*context_size)
def forward(self, x):
# the size of x, (batch_size, context_size=2, word_index)
# the size of embedding(x), (batch_size, context_size=2, embedding_dim)
# the size of embeds, (batch_size, context_size*embedding_dim)
batch_size = x.size(0)
embeds = self.embeddings(x).squeeze(1)
output = F.relu(self.linear1(embeds)) # batch_size*128
output = F.log_softmax(self.linear2(output),dim=1).view(batch_size, self.vocab_size, self.context_size) # batch * vocab_size*context_size
output = output.permute(0,2,1)# batch * context_size * vocab_size
return output
The code of Training
I calculate the loss separately to solve the problems. We know the output size is (batch_size, context_size, vocab_size),and the target size is (batch_size, context_size).
So, we use calculate the loss, loss_function(log_probs[:,0,:], targetData[:,0]), and the size of log_probs[:,0,:] is (batch_size, vocab_size), and the size of targetData[:,0] is (batch_size, ), then, we can use the loss_function to solve this multi-classification problem.
NUM_EPOCH = 100
losses = []
loss_function = nn.NLLLoss()
model = SkipGram(lang_process.n_words, embedding_dim=30, context_size=2)
optimizer = optim.Adam(model.parameters(), lr=0.05)
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
#Training Start
for epoch in range(NUM_EPOCH):
total_loss = 0
exp_lr_scheduler.step()
for num, (trainData, targetData) in enumerate(train_loader):
# forward
log_probs = model(trainData)
# We calculate two values separately.(the loss of the first word of output + the loss of the second word of output)
loss = loss_function(log_probs[:,0,:], targetData[:,0])
loss = loss + loss_function(log_probs[:,1,:], targetData[:,1])
# b-p
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Get the Python number from a 1-element Tensor by calling tensor.item()
total_loss += loss.item()
losses.append(total_loss)
if (epoch+1) % 5 == 0:
print('Epoch : {:0>3d}, Loss : {:<6.4f}, Lr : {:<6.7f}'.format(epoch, total_loss, optimizer.param_groups[0]['lr']))
And, I want to know is there any other way to solve the problem?