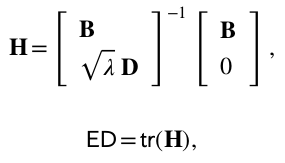I am training a model that needs to calculate the inverse of a [batchSize, 512, 512] matrix in the loss calculations. However, adding this step causes training to go from ~20min/epoch to ~2.5hrs/epoch. That’s even with jit scripting the function. The documentation says that almost all torch.linalg functions using CUDA will synchronize with the CPU.
Can anyone explain why this is necessary and, more importantly, how I can speed this up? I need to train multiple models and I don’t have 2-3 weeks for each one. My current idea is to generate an index matrix at initialization, use torch.gather to separate the minors, calculate all the determinants, and then reshape it. Is there an easier way?
You have a batch of batchSize512x512 matrices, and you need to
invert each of these matrices individually. Is this correct?
You say that you do this in the loss calculations. Do you then need to backward() through the matrix inversions, or do the inversions not
participate directly in the backpropagation?
This seems out of whack. How many total samples do you have in one
epoch? That is, what is batchSize and how many batches do have in
one epoch?
I can invert a 512x512 matrix in about 4 msec. on my gpu, and I can
invert and backpropagate through the inversion in about 13 msec. So
you would have to have a lot of samples (about half a million) in an
epoch for an inversion plus backpropagation to account for the two-hour
increase in your training time.
Here is a timing script:
import torch
print (torch.__version__)
print (torch.cuda.get_device_name (0))
import time
def minv_time (b, n = 1):
print ('torch.minv():')
print ('b.shape:', b.shape, ' b.device:', b.device)
cnt = 0
n_warm = 2
for i in range (n_warm):
for m in b:
minv = torch.inverse (m)
tm_start = time.time()
torch.cuda.synchronize()
for i in range (n):
for m in b:
minv = torch.inverse (m)
cnt += 1
torch.cuda.synchronize()
tm = time.time() - tm_start
print ('tm:', tm, ' cnt:', cnt, ' tm / cnt:', tm / cnt)
def minv_backward_time (b, n = 1):
print ('torch.minv() with backward():')
print ('b.shape:', b.shape, ' b.device:', b.device)
b = b.clone ()
b.requires_grad = True
cnt = 0
n_warm = 2
for i in range (n_warm):
for m in b:
minv = torch.inverse (m)
minv.sum().backward()
tm_start = time.time()
torch.cuda.synchronize()
for i in range (n):
for m in b:
minv = torch.inverse (m)
minv.sum().backward()
cnt += 1
torch.cuda.synchronize()
tm = time.time() - tm_start
print ('tm:', tm, ' cnt:', cnt, ' tm / cnt:', tm / cnt)
def mm_time (b, n = 1):
print ('torch.mm():')
print ('b.shape:', b.shape, ' b.device:', b.device)
cnt = 0
n_warm = 2
for i in range (n_warm):
for m in b:
mm = torch.mm (m, m)
tm_start = time.time()
torch.cuda.synchronize()
for i in range (n):
for m in b:
mm = torch.mm (m, m)
cnt += 1
torch.cuda.synchronize()
tm = time.time() - tm_start
print ('tm:', tm, ' cnt:', cnt, ' tm / cnt:', tm / cnt)
def bmm_time (b, n = 1):
print ('torch.bmm():')
print ('b.shape:', b.shape, ' b.device:', b.device)
n_op = 0
n_warm = 2
for i in range (n_warm):
bmm = torch.bmm (b, b)
tm_start = time.time()
torch.cuda.synchronize()
for i in range (n):
bmm = torch.bmm (b, b)
n_op += b.size (0)
torch.cuda.synchronize()
tm = time.time() - tm_start
print ('tm:', tm, ' n_op:', n_op, ' tm / n_op:', tm / n_op)
_ = torch.manual_seed (2022)
bm_cpu = torch.randn (100, 512, 512)
bm_gpu = bm_cpu.cuda()
minv_time (bm_cpu, 10)
minv_time (bm_gpu, 10)
minv_backward_time (bm_cpu, 10)
minv_backward_time (bm_gpu, 10)
mm_time (bm_cpu, 10)
mm_time (bm_gpu, 10)
bmm_time (bm_cpu, 10)
bmm_time (bm_gpu, 10)
(This script also looks at cpu and matrix-multiplication timings for context
and comparison.)
First, figure out the apparent mismatch between my naive understanding
of your use case and my timing results.
However, if you really are performing something like half a million
inversions per epoch, then I doubt that you will be able to get much
speed-up.
There could be some significant inefficiency in pytorch’s gpu handling
of this sort of basic linear algebra (that you could work around), but that
seems very unlikely to me. I would trust pytorch to be highly optimized
for such basic building blocks.
In general, linear algebra for large (and large-ish) matrices is “expensive”
(matrix inversion and matrix multiplication both scale as n^3 for n x n
matrices), but – as my timings show – for 512 x 512 matrices, it’s not
that expensive.
Some possible suggestions:
Do your matrices have special structure (say, being block-diagonal) that
could make them cheaper to invert? If so, you could use a specialized
(and cheaper) inversion algorithm.
Do you in fact need the entire inverse of the matrices? For example, if
you are solving a “single” linear algebra problem that uses the matrix
(which would correspond, roughly speaking, to computing a single
column of its inverse), this can be performed more cheaply than the
full inversion (although it does still scale as n^3).
Just to be clear, if your matrix is constant across samples, or your
batch of matrices is constant across batches, you should pre-compute
and cache the inverse(s) once at the beginning, and then re-use the
pre-computed inverse(s) over and over again for each epoch.
If, however, your matrices to be inverted are the result of the forward
pass (so that you’re not inverting the same matrix multiple times), then
trying to implement your own inversion routine by calculating the
determinants of the minors (the cofactors) won’t do you any good,
and will almost certainly slow things down (significantly).
Thank you for your reply! You hit the nail on the head. I have half a million samples in each epoch and I need to backpropagate through the inversions. However, I don’t need the full inverse, but it’s complicated. I’m implementing the following equation, where B is a 60x512 matrix, D is 512x512, and lambda is a predicted value. Even though the indices will always be the same, the matrices come from the forward pass. But, since the bulk of the second matrix is 0-padded, I can cut down on how much of the inverse I need to calculate. So I need to include all the columns but only the first 60 rows.
Unfortunately, I haven’t found an easy way to implement this. I have code to generate the indices and calculate everything, but a matrix like that is hard to handle given the memory constraints.
Maybe my best bet is a feature request that allows us to specify partial inverses. Or maybe they can find an alternative to synchronizing with the CPU.
There are a number of things that could be said about this, but I
don’t really understand what you are doing.
Let me call the matrix you are trying to “invert” M, and write it out
as [[B], [sqrt (lambda) * D]].
I therefore suppose that M is a 572 x 512 matrix. (If not, what is it?)
As such, it is not square, and does not have an inverse.
Are you imagining that the “inverse” is some sort of pseudoinverse?
(This could make sense, depending on what you are doing.) I could
speculate, but better that you clarify the details of what your equation
means.
I don’t know whether it would be relevant to your use case, but you can
think of the LU decomposition of a matrix as being a “partial inverse” in
that you can use it to solve multiple equations, M @ x = v, with the same
matrix, M, but different vector right-hand-sides, v, without computing the
full inverse of M, but also not starting from scratch each time.
I don’t understand why you are so fixated on this cpu synchronization.
In my timing tests (that seem to correspond to your two-hour per epoch
run-times) my gpu was nearly saturated at 98%. If you need two hours
of gpu time, that’s how much time you need (even if the synchronization
did represent an unnecessary cpu inefficiency, which I doubt, because I
trust pytorch on these basic building blocks).