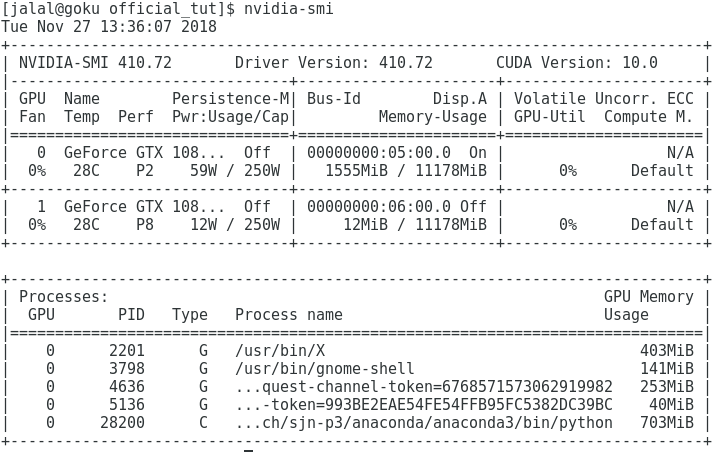
This is output of nvidia-smi right after I get the error:
It was working before because dataloader only had 49 samples in it. Now it has 863 samples in it.
Complete error log:
Using sample 0 as test data
Resetting model
Epoch 0/24
----------
Exception ignored in: <bound method _DataLoaderIter.__del__ of <torch.utils.data.dataloader._DataLoaderIter object at 0x7fa90b043c18>>
Traceback (most recent call last):
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 399, in __del__
self._shutdown_workers()
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 378, in _shutdown_workers
self.worker_result_queue.get()
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/queues.py", line 337, in get
return _ForkingPickler.loads(res)
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/site-packages/torch/multiprocessing/reductions.py", line 151, in rebuild_storage_fd
fd = df.detach()
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/connection.py", line 737, in answer_challenge
response = connection.recv_bytes(256) # reject large message
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError: [Errno 104] Connection reset by peer
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-4-9365fbc2464a> in <module>()
34 model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, sample, target, num_epochs=10)'''
35
---> 36 model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, dataloader, num_epochs=25)
37
38 # Test on LOO sample
<ipython-input-2-305560153b80> in train_model(model, criterion, optimizer, scheduler, dataloader, num_epochs)
33 loss = criterion(outputs, labels)
34 # backward + optimize only if in training phase
---> 35 loss.backward()
36 optimizer.step()
37 # statistics
/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph)
91 products. Defaults to ``False``.
92 """
---> 93 torch.autograd.backward(self, gradient, retain_graph, create_graph)
94
95 def register_hook(self, hook):
/scratch/sjn-p3/anaconda/anaconda3/lib/python3.6/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
88 Variable._execution_engine.run_backward(
89 tensors, grad_tensors, retain_graph, create_graph,
---> 90 allow_unreachable=True) # allow_unreachable flag
91
92
RuntimeError: CuDNN error: CUDNN_STATUS_EXECUTION_FAILED
I am using resnet50 as a base model. I am not sure if it has batchnorm module and how to set it as 16. Is there a link for that? Do you suggest doing so?
At this point, I am not sure if the error is because I have ran out of the memory. I just picked a wild guess because the only thing that changed from my other experiment was the number of images passed to train_model via dataloader from 49 to 863. I am also not sure how to investigate this further.