Model A and B have same structure, same initialization. (A does not has data).
After model B trains and do model_B.backward(), it has gradient.
How to copy all gradient from B to A so that after optimizer_A.step() and optimizer_B.step(), both have same weight.
I tried:
for A, B in zip(model_A.named_parameters(), model_B.named_parameters()):
A[1].grad = B[1].grad
But it didn’t work. The result is like this:
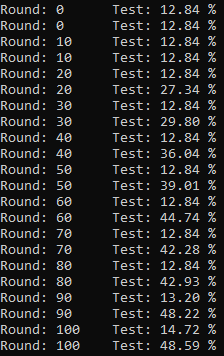
On each round, the first line is accuracy of A and the second line is accuracy of B.