Hi guys,
Please I need help, I am new to using Torch and also new to use LSTM, I am working on time series sales forecasting for a dataset with the following data structure:
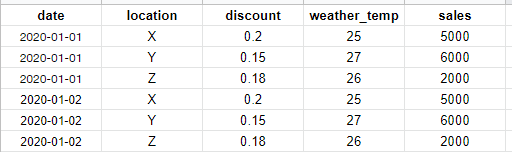
I wanna do nn.embeddings (as I have read it acts like one hot encoding) to the locations, so that instead of running an individual model for each location, run one model for all the data. So, the final structure should be like that:
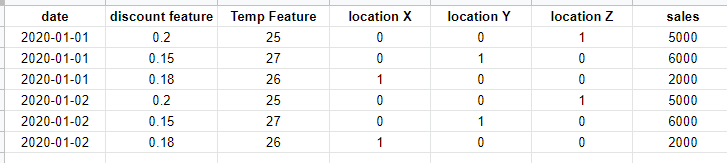
what parameters should I pass to nn.embeddings?
Given that my data loading function is as follows:
def sliding_windows(data, seq_length):
x = []
y = []
for i in range(len(data)-seq_length-1):
_x = data[i:(i+seq_length)]
_y = data[i+seq_length]
x.append(_x)
y.append(_y)
return np.array(x),np.array(y)
sc = MinMaxScaler()
training_data = sc.fit_transform(training_set)
seq_length = 4
x, y = sliding_windows(training_data, seq_length)
y = (y[:,0]).reshape(y[:,0].shape[0],1)
train_size = int(len(y) * 0.9)
test_size = len(y) - train_size
dataX = Variable(torch.Tensor(np.array(x)))
dataY = Variable(torch.Tensor(np.array(y)))
trainX = Variable(torch.Tensor(np.array(x[0:train_size])))
trainY = Variable(torch.Tensor(np.array(y[0:train_size])))
testX = Variable(torch.Tensor(np.array(x[train_size:len(x)])))
testY = Variable(torch.Tensor(np.array(y[train_size:len(y)])))
and the model is as follows:
class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers):
super(LSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
c_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
# Propagate input through LSTM
ula, (h_out, _) = self.lstm(x, (h_0, c_0))
h_out = h_out.view(-1, self.hidden_size)
out = self.fc(h_out)
return out
and finally the training loop is as follows:
num_epochs = 1000
learning_rate = 0.008
input_size = 4
hidden_size = 4
num_layers = 1
num_classes = 1
lstm = LSTM(num_classes, input_size, hidden_size, num_layers)
criterion = torch.nn.MSELoss() # mean-squared error for regression
optimizer = torch.optim.Adam(lstm.parameters(), lr=learning_rate,weight_decay=0.001)
# Weight_decay to decay the errors == regularization technique
# optimizer = torch.optim.SGD(lstm.parameters(), lr=learning_rate)
# Train the model
for epoch in range(num_epochs):
outputs = lstm(trainX)
optimizer.zero_grad()
# obtain the loss function
loss = criterion(outputs, trainY)
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
and what should I do as well for prediction part?
Thanks in advance