I have trained cifar10 to classify using this Vgg16 model, but the accuracy is not improving. However, loss_val is dropping well. How can I improve the accuracy? I have seen other papers that go 96%, etc.
class VGG16(nn.Module):
def __init__(self): # , num_classes):
super(VGG16, self).__init__()
num_classes=10
self.block1_output = nn.Sequential (
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block2_output = nn.Sequential (
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block3_output = nn.Sequential (
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block4_output = nn.Sequential (
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block5_output = nn.Sequential (
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512), #512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 32 ), #4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(32, num_classes), #4096
)
def forward(self, x):
x = self.block1_output(x)
x = self.block2_output(x)
x = self.block3_output(x)
x = self.block4_output(x)
x = self.block5_output(x)
#print(x.size())
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def train(model,train_loader,device):
# 交差エントロピー
criterion = nn.CrossEntropyLoss()
# 確率的勾配降下法
model =model.train()
optimizer = optim.AdamW(model.parameters(), lr=0.004)
loss_values = []
for epoch in range(100):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
#print(i)
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs.to(device))
loss = criterion(outputs, labels.to(device))
# 誤差逆伝播
loss.backward()
optimizer.step()
train_loss = loss.item()
running_loss += loss.item()
if i % 500 == 499:
#print('[%d, %5d] loss: %.20f' % (epoch + 1, i + 1, running_loss / 500))
loss_values.append(running_loss/500)
running_loss = 0.0
plt.plot(loss_values)
plt.show()
#print('Finished Training')
return model
def val(model,val_dataloader,device):
model = model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in val_dataloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
#print(outputs.data)
#print((predicted == labels).sum())
correct += (predicted == labels).sum().item()
print('Accuracy of the network on images: %d %%' % (100 * correct / total))
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = (v.VGG16()).to(device)
# ToTensor:画像のグレースケール化(RGBの0~255を0~1の範囲に正規化)、Normalize:Z値化(RGBの平均と標準偏差を0.5で決め打ちして正規化)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# トレーニングデータをダウンロード
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True, num_workers=0)
# テストデータをダウンロード
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
val_dataloader = torch.utils.data.DataLoader(testset, batch_size=10, shuffle=True, num_workers=0)
#train_loader = torch.load("D:\Imagetrain.pt")
#train_dataloader = data.DataLoader(train_loader, batch_size = 100, shuffle = True)
#val_loader = torch.load("D:\Imagevalid.pt")
#val_dataloader = data.DataLoader(val_loader, batch_size = 100, shuffle = True)
print("VGG16")
model = train(model,train_loader,device)
val(model,val_dataloader,device)
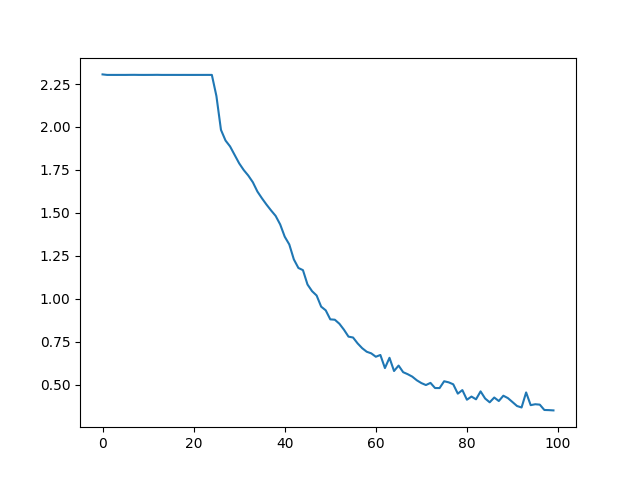
This image shows the loss_val transition.
accuracy:
Accuracy of the network on images: 76 %