Hello ![]() ,
,
I am new to PyTorch, and I built an LSTM model with Embeddings to predict a target of size 720 using time series data with a sequence of length 14 and more than 18 000 features (which includes date related data).
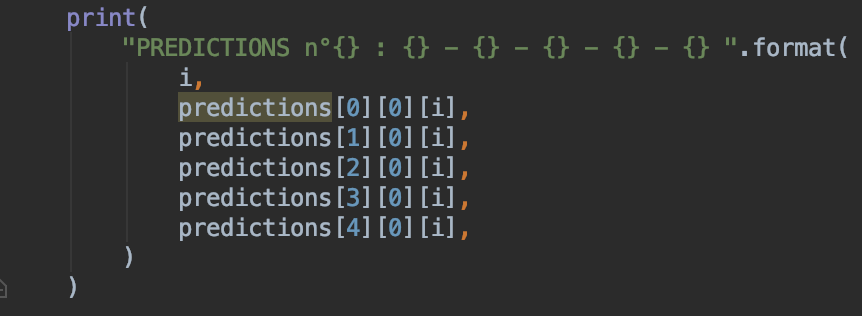
The problem is that my model always outputs the average of all the labels he saw during training, so to make it sure it’s true, I tried to overfit my model on a single batch of size 5 and the results confirm what I thought:
The two screenshots above show the predictions of the model regarding the 86th component of the five targets of the batch, and the same for the 57th one, as you can see it’s nearly the average that’s predicted.
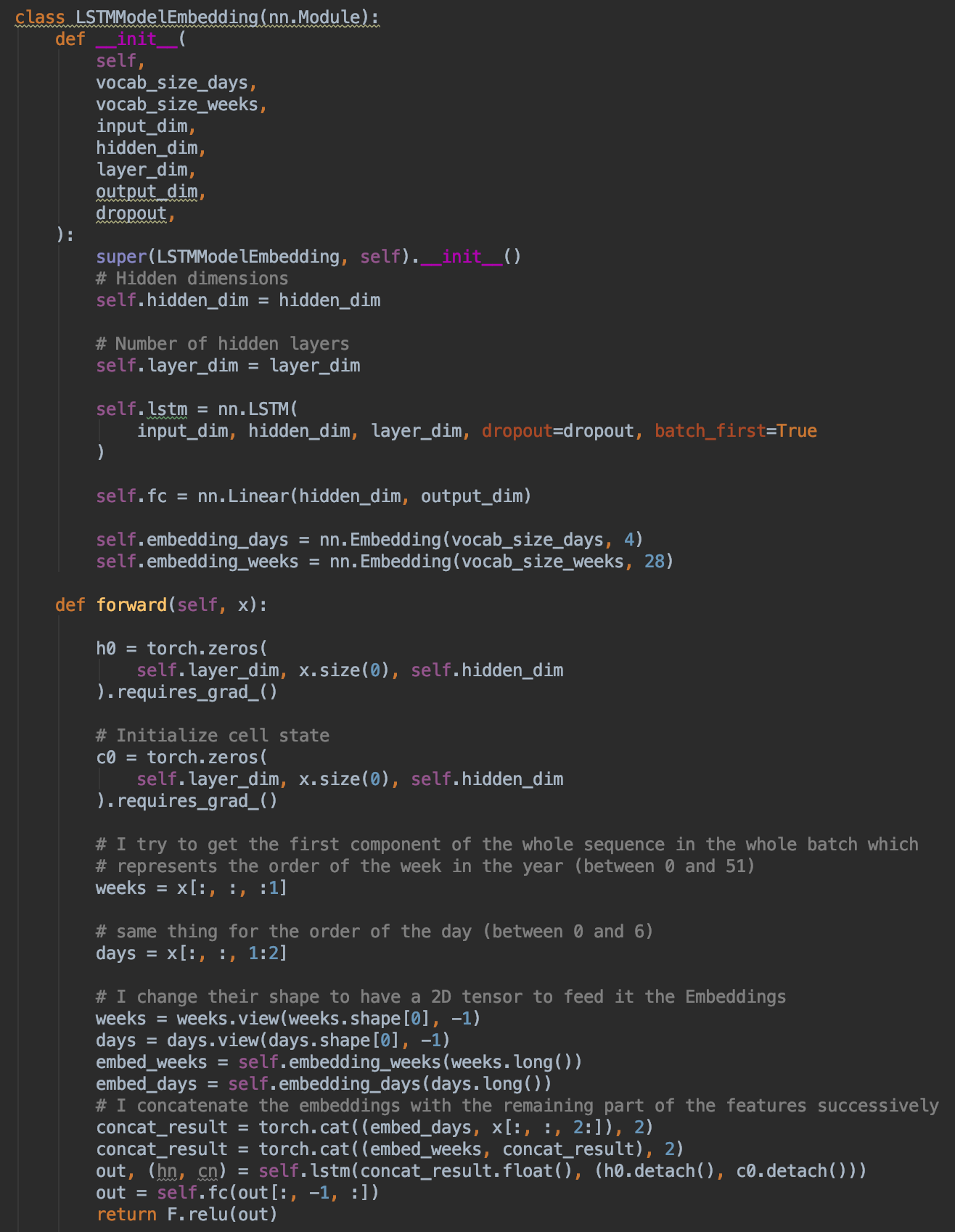
This is the code of the model :
This is how I made the training :

1 - I don’t know what I am doing wrong since the model can’t predict exactly for each input, but always gives the output of the targets in the training set.
The L1 Loss doesn’t decrease to 0 obviously but get stuck around 0,98 for the training data
2- I would also like to know If the Embeddings are very well used in this case, because I tried to encode the two variables related to datetime (week and day) as you can see in the code above, and concatenated them with the remaining features to feed them after to the LSTM.
In the first Embedding for the weeks, I go from a vocabulary of size 52 to an embedded vector of size 28.
In the second one for the days, I go from a vocabulary of size 7 to an embedded vector of size 4.
If there’s anything wrong in the code, please don’t hesitate to mention it ![]() , maybe that’s the reason my model can’t overfit, and learn very well.
, maybe that’s the reason my model can’t overfit, and learn very well.
NB : For the input that I gave to the model, it’s a sequence of length 14 which represent 14 successive days where I give to the model all the features WITH their corresponding target in the input, and for the corresponding output it’s the target of the day AFTER,
Thank you very much ! ![]()