hello everyone,
if someone can help me
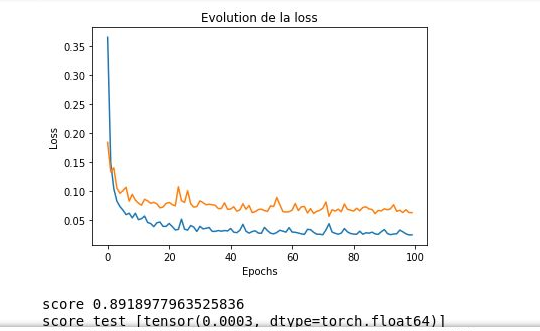
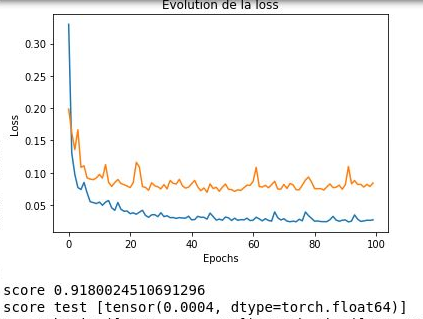
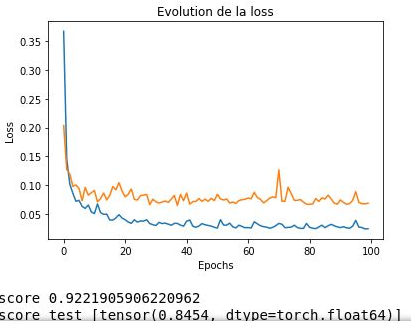
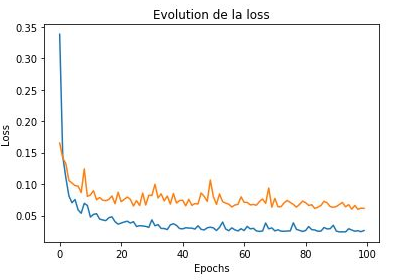
my problem is that i’m using kfols method to do the cross validation, which means that i have 5 itération to fit my data into training and testing set
i made a loop for around my data, when i do just a training it works normally but when i do the validation after that, i get this error RuntimeError: CUDA error: an illegal memory access was encountered
knowing that i tryed
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
print(‘Using device:’, device)
print()#Additional Info when using cuda
if device.type == ‘cuda’:
print(torch.cuda.get_device_name(0))
print(‘Memory Usage:’)
print(‘Allocated:’, round(torch.cuda.memory_allocated(0)/10243,1), ‘GB’)
print('Cached: ', round(torch.cuda.memory_cached(0)/10243,1), ‘GB’)
and i get
Using device: cuda
GeForce GTX 1080 Ti
Memory Usage:
Allocated: 0.4 GB
Cached: 1.9 GB
here is my code :
for l in range(0,len(XTrain)):
loss=0.0 loss_test=0.0 Net=UNet(1,4) Net.apply(init_weights) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # torch.backends.cudnn.benchmark = True # torch.cuda.set_device(0) Net.to(device) size=[] size_test=[] taille=[] x={} y={} z={} x_test={} y_test={} z_test={} data_train_norm=[] data_test_norm=[] gt_train_norm=[] gt_test_norm=[] for k in range(0,int(0.8*len(data_ed))): data_train_norm.append(Preprocessing(XTrain[l][k])) gt_train_norm.append((YTrain[l][k])) size.append(data_train_norm[k].shape) x[k],y[k],z[k]=size[k] for k in range(0,int(0.2*len(data_ed))): data_test_norm.append(Preprocessing(XTest[l][k])) gt_test_norm.append((YTest[l][k])) size_test.append(data_test_norm[k].shape) x_test[k],y_test[k],z_test[k]=size_test[k] image_resized_train=[] image_resized_test=[] image_resized_train_gt=[] image_resized_test_gt=[] for i in range(0,int(0.8*len(data_ed))): for j in range(z[i]): image_resized_train.append(resize_image(data_train_norm[i][:,:,j],H_train[l][i][1],1.25)) image_resized_train_gt.append(resize_gt(gt_train_norm[i][:,:,j],H_train[l][i][1],1.25)) for i in range(0,int(0.2*len(data_ed))): for j in range(z_test[i]): image_resized_test.append(resize_image(data_test_norm[i][:,:,j],H_test[l][i][1],1.25)) image_resized_test_gt.append(resize_gt(gt_test_norm[i][:,:,j],H_test[l][i][1],1.25)) final_train=[] final_test=[] final_train_gt=[] final_test_gt=[] img_train=[] img_test=[] img_train_gt=[] img_test_gt=[] width=557 height=667 data_tensor_test=[] data_tensor_train=[] gt_tensor_test=[] gt_tensor_train=[] for i in range(0,len(image_resized_train)): img_train.append(Resize(image_resized_train[i],width,height)) final_train.append(crop(img_train[i],256,256)) data_tensor_train.append(torch.from_numpy(np.array(final_train[i])).float()) # groudtruth train img_train_gt.append(Resize(image_resized_train_gt[i],width,height)) final_train_gt.append(crop(img_train_gt[i],256,256)) gt_tensor_train.append(torch.from_numpy(np.array(final_train_gt[i])).float()) for i in range(0,len(image_resized_test)): img_test.append(Resize(image_resized_test[i],width,height)) final_test.append(crop(img_test[i],256,256)) data_tensor_test.append(torch.from_numpy(np.array(final_test[i])).float()) img_test_gt.append(Resize(image_resized_test_gt[i],width,height)) final_test_gt.append(crop(img_test_gt[i],256,256)) gt_tensor_test.append(torch.from_numpy(np.array(final_test_gt[i])).float()) X_train=torch.stack(data_tensor_train) X_test=torch.stack(data_tensor_test) Y_train=torch.stack(gt_tensor_train) Y_test=torch.stack(gt_tensor_test) print(l,X_train.shape,X_test.shape,Y_train.shape,Y_test.shape) class LoadDataset_train(Dataset): def __init__(self): # load data self.X=X_train self.Y=Y_train self.len=X_train.shape[0] def __len__(self): # dataset's size return self.len def __getitem__(self, idx): X,Y = self.X[idx], self.Y[idx] # the position X = X.view(1,X.shape[0],X.shape[1]) sample=X,Y return sample class LoadDataset_test(Dataset): def __init__(self): # load data self.X=X_test self.Y=Y_test self.len=X_test.shape[0] def __len__(self): # dataset's size return self.len def __getitem__(self, idx): X,Y = self.X[idx], self.Y[idx] # the position X = X.view(1,X.shape[0],X.shape[1]) sample=X,Y return sample dataset=LoadDataset_train() trainloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=4, shuffle=True, num_workers=1) dataset_test=LoadDataset_test() trainloader_test = torch.utils.data.DataLoader(dataset=dataset_test, batch_size=1, shuffle=True, num_workers=1) # print(trainloader) learning_rate=10e-3 #define the weights using in the loss function weights = torch.tensor([0.07,0.31,0.31,0.31]).to(device) ######## #define a loss function criterion = nn.CrossEntropyLoss(weights) #define the optimizer aDAM optimizer=optim.Adam(Net.parameters(), lr=learning_rate , weight_decay=10e-8) n_epochs=10 loss_values=[] loss_values_test=[] for epoch in range(n_epochs): Net.train() running_loss = 0.0 for i, data in enumerate(trainloader): # get the inputs; data is a list of [inputs, labels] inputs, labels = data[0].to(device), data[1].to(device).long() optimizer.zero_grad() outputs=Net(inputs) loss=criterion(outputs,labels) running_loss+=loss.item() loss.backward() optimizer.step() print(i) loss_values.append(running_loss/len(trainloader)) running_loss_test=0.0 Net.eval() with torch.no_grad(): for j, data_test in enumerate(trainloader_test,0): inputs_test, labels_test = data_test[0].to(device), data_test[1].to(device).long() outputs_test=Net(inputs_test) loss_test=criterion(outputs_test,labels_test) running_loss_test+=loss_test.item() loss_values_test.append(running_loss_test/len(trainloader_test))
THANK YOU !!!