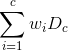Hi All,
I am trying to implement dice loss for semantic segmentation using FCN_resnet101. For some reason, the dice loss is not changing and the model is not updated.
import torch
import torchvision
import loader
from loader import DataLoaderSegmentation
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.utils.data.sampler import SubsetRandomSampler
from torch.autograd import Variable
batch_size = 1
validation_split = .2
shuffle_dataset = True
random_seed= 66
n_class = 2
num_epochs = 5
lr = 1e-4
momentum = 0.9
w_decay = 1e-5
step_size = 50
gamma = 0.5
cw = [0.5028138887905369,89.34501791284346]
class_weight=torch.FloatTensor(cw).cuda()
traindata = DataLoaderSegmentation('/home/ubuntu/Downloads/imgs/lensonly')
trainloader = torch.utils.data.DataLoader(traindata)
class diceloss(torch.nn.Module):
def init(self):
super(diceLoss, self).init()
def forward(self,pred, target):
smooth = 1.
iflat = pred.contiguous().view(-1)
tflat = target.contiguous().view(-1)
intersection = (iflat * tflat).sum()
A_sum = torch.sum(iflat * iflat)
B_sum = torch.sum(tflat * tflat)
return 1 - ((2. * intersection + smooth) / (A_sum + B_sum + smooth) )
model =torchvision.models.segmentation.fcn_resnet101(pretrained=False,aux_loss=None,num_classes=2).cuda()
criterion = diceloss()
for iter in range(num_epochs):
for (i,l) in trainloader:
optimizer.zero_grad()
i= i.to(device)
l = l.to(device)
l[l!=0]=1
l=l.long()
outt = model(i)
pred = Variable(torch.argmax(outt['out'],1).float(),requires_grad=True).cuda()
loss = criterion(pred,l.squeeze(0).type(torch.cuda.FloatTensor))
loss.backward()
optimizer.step()
print(iter)
torch.save(model, '/home/ubuntu/Downloads/newnet.pth')
Any and all help is appreciated. I copy pasted dice loss from here
Please let me know if this is the correct way of implementing it.
Hello,
Your loss seems correct, have you different classes on your dataset?
Using argmax is probably not a good idea since it is not differentiable, you maybe should try to encode your labels in a one hot vector to overcome that problem.
Thanks for your reply, I am performing a binary segmentation where I have 2 classes. I am pretty new to this platform and deep learning in general. Is there a reference which I can look up to see how to perform the following
“you maybe should try to encode your labels in a one hot vector to overcome that problem.”
I am not sure but for me the problem is the fact that argmax is not a differentiable operation, so you have to overcome that.
If I resume, the output of your network is Nx2xHxW right ? Your idea is to take the argument max of the 2 classes and create your prediction with that information because your target is only NxHxW. The idea is to transform your target into Nx2xHxW in order to match the output dimension and compute the dice loss without applying any argmax. To transform your target from NxHxW into Nx2xHxW you can transform it to a one-hot vector like:
labels = F.one_hot(labels, num_classes = nb_classes).permute(0,3,1,2).contiguous() #in your case nb_classes = 2
Basically, one_hot will put 1 where the class is and 0 otherwise. (you can check the doc it is more clear than my explanation) The output of one_hot is NxHxWxC so you have to permute to obtain NxCxHxW.
After this transformation on your target, you should be able to compute the Dice Loss. (so you have also to make small changes in the forward of your loss)
Yes exactly, you will compute the “dice loss” for every channel “C”.
The final loss could then be calculated as the weighted sum of all the “dice loss”.
Something like :
where c = 2 for your case and wi is the weight you want to give at class i and Dc is like your diceloss that you linked but slightly modificated to handle one hot etc
Strangely, I haven’t found a differentiable multi-class dice loss online. Even the one on torchmetrics seems to not be a differentiable Dice coefficient metric.
I came up with this code for using Dice as a multi-class loss. Posting here in case anyone else is stuck, and may find it useful.
class MulticlassDiceLoss(nn.Module):
"""Reference: https://www.kaggle.com/code/bigironsphere/loss-function-library-keras-pytorch#Dice-Loss
"""
def __init__(self, num_classes, softmax_dim=None):
super().__init__()
self.num_classes = num_classes
self.softmax_dim = softmax_dim
def forward(self, logits, targets, reduction='mean', smooth=1e-6):
"""The "reduction" argument is ignored. This method computes the dice
loss for all classes and provides an overall weighted loss.
"""
probabilities = logits
if self.softmax_dim is not None:
probabilities = nn.Softmax(dim=self.softmax_dim)(logits)
# end if
targets_one_hot = torch.nn.functional.one_hot(targets, num_classes=self.num_classes)
print(targets_one_hot.shape)
# Convert from NHWC to NCHW
targets_one_hot = targets_one_hot.permute(0, 3, 1, 2)
# Multiply one-hot encoded ground truth labels with the probabilities to get the
# prredicted probability for the actual class.
intersection = (targets_one_hot * probabilities).sum()
mod_a = intersection.sum()
mod_b = targets.numel()
dice_coefficient = 2. * intersection / (mod_a + mod_b + smooth)
dice_loss = -dice_coefficient.log()
return dice_loss
# end class MulticlassDiceLoss
criterion = MulticlassDiceLoss(num_classes=3, softmax_dim=1)
y = torch.randn(10, 3, 4, 4)
ground_truth = torch.randint(0, 3, (10, 4, 4))
print(y.shape)
criterion(y, ground_truth)
The loss function is differentiable if the individual components are piecewise differentiable. Typically non-differentiable operations that cause the loss function to be non-differentiable include (but are not limited to).
max
argmax
clip
The function above uses ADD, MUL, LOG, DIV, which are all differentiable operations.