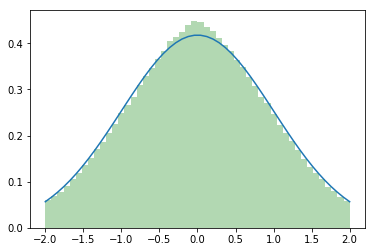
This seems to be the picture I had in mind when I said that it was with cutting off too much by restricting to the circle…
If you can do with an approximation, torch.fmod(torch.randn(size),2) might be easiest.
It moves more of the cut-off mass to the center than to the boundaries, but at least the good samples stay where they belong…