I am working on a CNN to make directional predictions of a market based on a visual representation of the recent market state. The model can make three classifications, down, zero and up. I use the torch.nn.functional.cross_entropy function to determine the loss, which does its job.
However, for practical purposes I want to specifically optimize the precision score of the up and down predictions. To do this, I need to penalize up-predictions that are actually down harder than misclassified zero-predictions for example. I have an evenly distributed set of labels and I know I can apply loss_weight to force more zero-predictions, which slightly improves the precision scores for the up and down predictions.
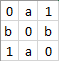
However, I am looking to apply a weight matrix instead of a vector to more specifically dictate loss, looking to further improve precision. Example of such a matrix would be the following:
,
where 0<a<b<1
Is there any built-in functionality for this in Pytorch, or does this require me to do tinkering ‘under the hood’?
I’m not sure how your actual prediction look like, but assuming they would have the same shape as your weight matrix, you could simply multiply both before calling loss.backward().
I will clarify a little. The output_logits in the code below are torch.Size([128, 3]), a vector of 3 logit probabilities for every observation. My adjusted loss weights loss_mod is a 3*3 matrix.
I think I need the loss function to use this matrix along with the input and target. If I correctly understand how optimizing works, the direction in which the parameters are changed depends on the derivative of the loss function, right?
Looking at it more closely, I am wondering how loss.backward() and optimizer.step() are actually connected…
 ,
,