As mentioned in the title~
Thank you!!!
Thank you very much!!!
Above is the official tutorial of pytorch for combining the CUDA and Pytorch…Seems the torch library can not be used in GPU, right? Like at:: torch:: aten::, they can only be used in cpp file?
So on GPU, the only library we can use is… provided by NVIDIA company like cublas, cusparse?
Thank you!!!
No, you can use libtorch with a GPU. Take a look at e.g. lltm_cuda_kernel.cu in the linked tutorial.
Aten methods work on different devices (similar to how the Python API can use tensors on the CPU and GPU).
You are of course able to call into cublas etc. manually or you could use the ATen method (e.g. at::matmul) which will call into cublas internally. Other methods would call into other libs or a native PyTorch CUDA kernel.
1 Like
Thank you very much!!!
Uploading: image.png…
Well, I think torch can not be used in GPU, I mean, kernel function with global, like here, bugs show:
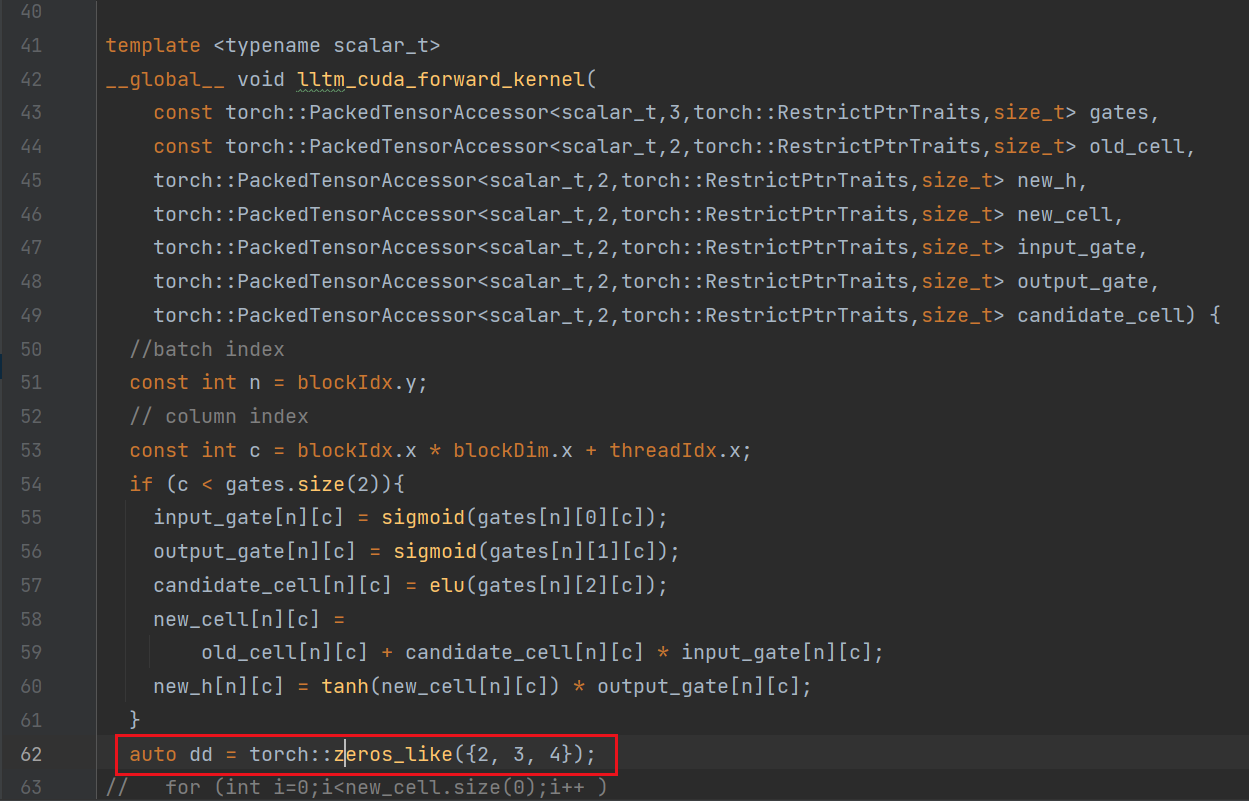
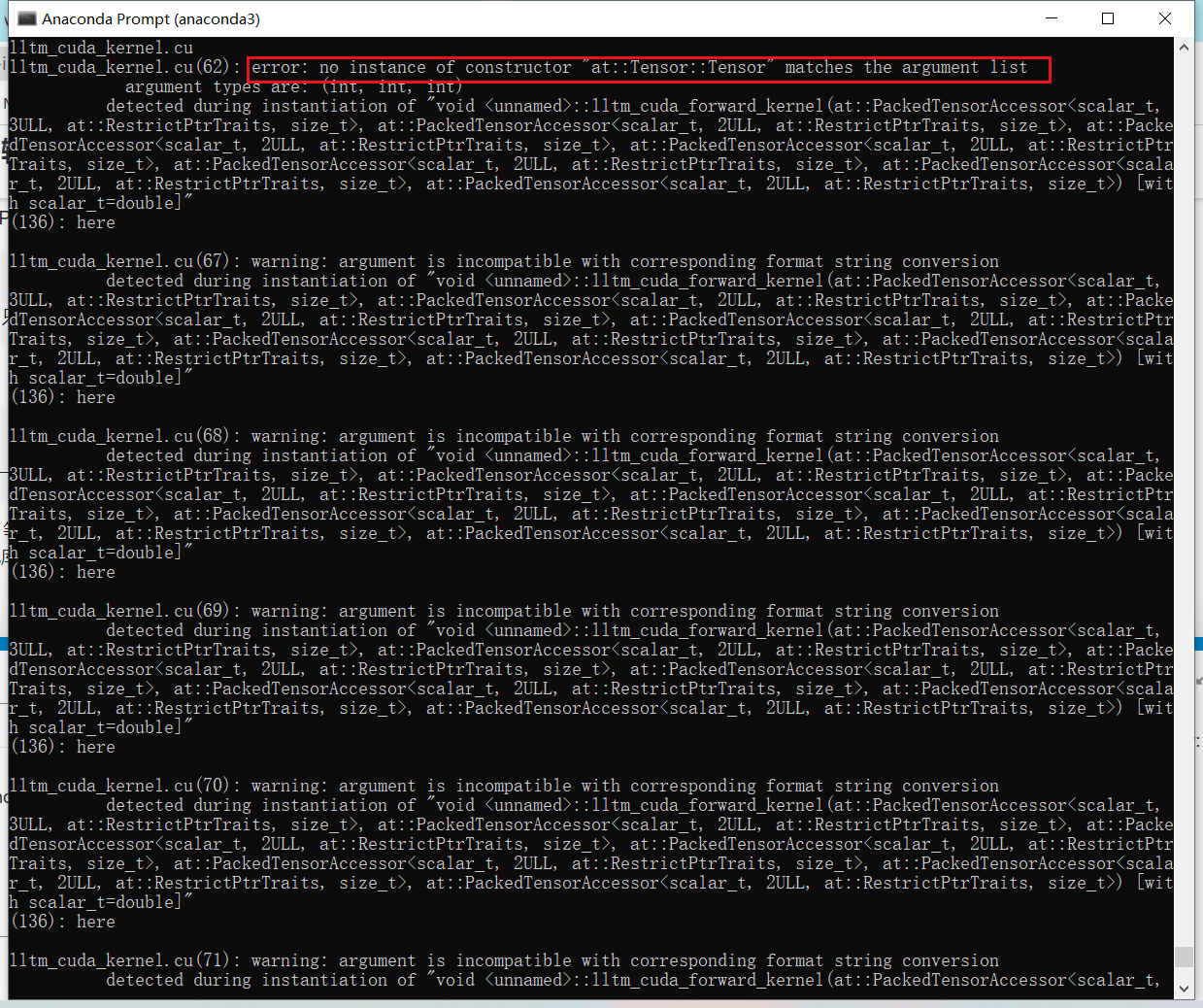
error: no instance of constructor “at::Tensor::Tensor” matches the argument list
argument types are: (int, int, int)
Well, I see lots of torch function in the .cu file (in official tutorial), but they are in the host function, which is on CPU… And no torch function on global or device function~
Well, I noticed even cublas is running in host function, I guess, even in host function does not necessarily mean this is running on CPU, just like if we use torch::mm in host function, if the data are on GPU, the calculation will be done on GPU? (Guarantee? should we obviously set calculation on GPU?)
Thank you!!!
Take a look at e.g. the CUDA programming model - Kernels, which explains the __global__ declaration specifier and explains how code is executed on the GPU.
In summary: PyTorch can use the GPU through native kernels, extensions, as well as CUDA libraries.
1 Like