PyTorch Forums
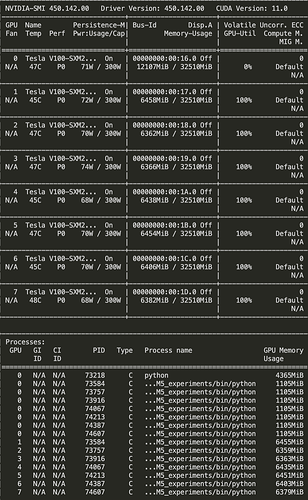
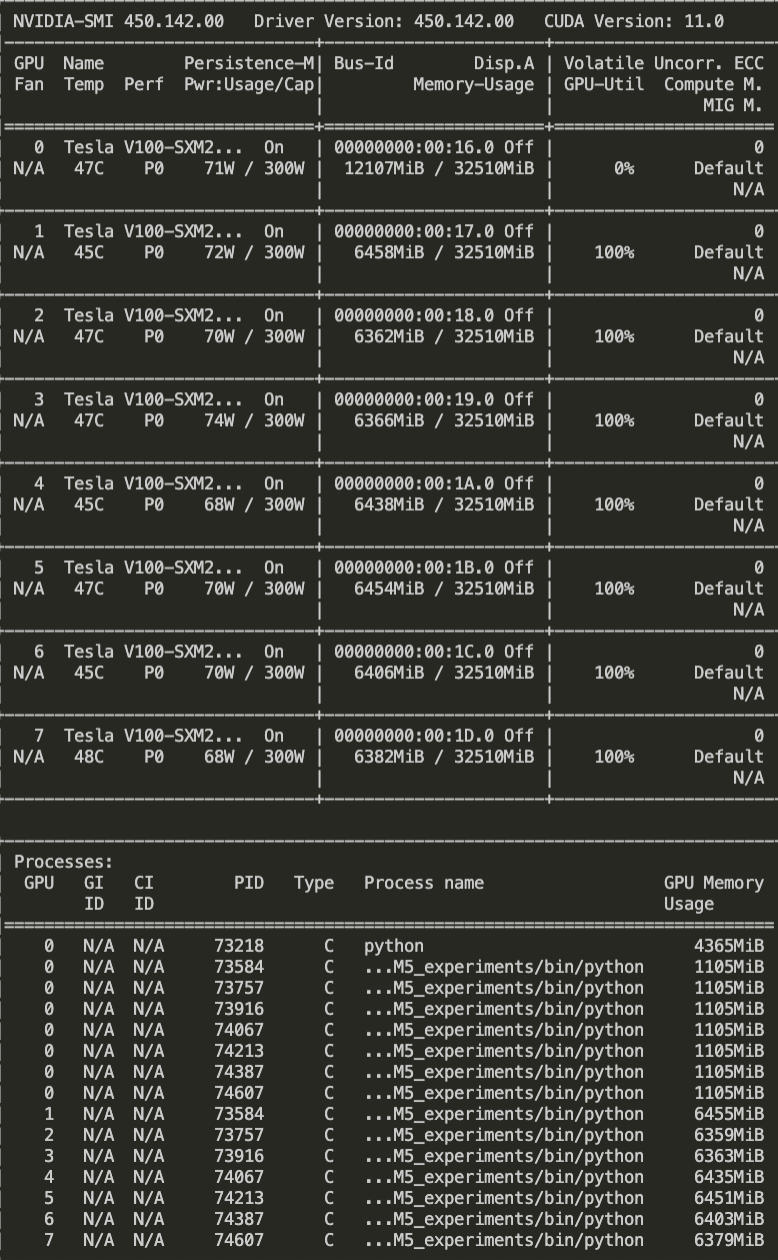
In DistributedDataParallel training additional n-1 processes are using memory on the first GPU, n being the number of GPUs
distributed
Ratul_Ghosh
(Ratul Ghosh)
September 9, 2022, 1:24am
1
Screen Shot 2022-09-08 at 5.46.25 PM
778×1260 204 KB