Hi.
Me and another colleague have been struggling on this problem for the last days and we are losing our sanity. Unfortunately the conditions to recreate this problems are so rare and fragile that I have to attach a ~600Mb data file to this post for people interested to reproduce this. This data file does not contain any personal or sensible data, it’s just some random Monte Carlo numbers generated by another program.
Anyway here is the problem:
We have a really simple model: 7 input neurons, going to 5 and then a single output. Everything is made with linear layer and with sigmoid activations. In the example below, the model doesn’t even need to be trained for this problem to appear.
When we evaluate this model on some large datasets (~10 Million points), there are some inconsistencies between the CPU and GPU evaluations. In particular, the CPU is always right but the GPU starts giving some random results after about 2 Million points.
Here are some plots that show this behavior:
-
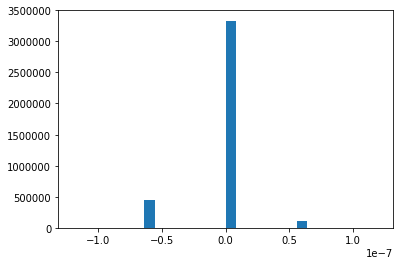
histogram of the difference between cpu evaluations and gpu evaluations. You can see a peak at 0 where the two evaluations coincide
-
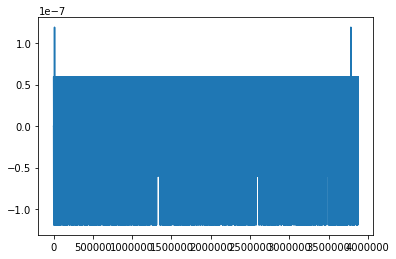
plot of the same difference. You can see that the two evaluations coincide for the first 2 Million points and then it becomes noise.
If you want to reproduce these plots here is a minimal working code:
import torch, os, h5py
from torch import nn
import matplotlib.pyplot as plt
class Model(nn.Module):
def __init__(self, input_dim, output_dim, hidden_units):
super(Model, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_units, bias = False)
self.fc2 = nn.Linear(hidden_units, output_dim, bias = False)
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
return x
#create the model
model = Model(7, 1, 5)
#read the data file
data = h5py.File(os.getcwd() + '/data.h5', 'r')
test_input = torch.Tensor((data['Data'])[()])
#shuffle the data
test_input = test_input[torch.randperm(test_input.size(0))]
#get indices for which variable 6 is between 350 and 450
idx1 = test_input[:, 6] > 350
idx2 = test_input[:, 6] < 450
#normalize data
norm_test_input = (test_input - test_input.mean(0))/test_input.std(0)
#take only data between 350 and 450
test_input_cut = norm_test_input[idx1 * idx2]
print(test_input_cut.shape)
# --- #
#evaluate the model on CPU
print("CPU")
with torch.no_grad():
print(model(test_input_cut)[-10:])
print(model(test_input_cut[-10:]))
cpu_results = model(test_input_cut)
#evaluate the model on GPU
print("GPU")
model.cuda()
test_input_cut = test_input_cut.cuda()
with torch.no_grad():
print(model(test_input_cut)[-10:])
print(model(test_input_cut[-10:]))
gpu_results = model(test_input_cut)
#plot difference between the two evaluations
diff = (cpu_results - gpu_results.cpu()).squeeze().numpy()
plt.hist(diff, bins = 30)
plt.show()
plx = range(cpu_results.size(0))
ply = (cpu_results.squeeze() - gpu_results.squeeze().cpu()).numpy()
plt.plot(plx, ply)
plt.show()
And here is the 600MB .h5 file (that needs to be put in the same folder of the python code) for which this problem appears.
This behavior is really fragile in this example: changing the two numbers (350 and 450) even slightly erases makes everything work fine. For different (or random generated) data we couldn’t find any “cut” that would make this appear, but from what we tried it doesn’t look like there are any problems with the input data. In the real case, i.e. in the full project code, this seems to happen more consistently. We can’t post the full source code, so this tiny fragile example is the only thing that we could come up with to reproduce the issue in a consistent way to be posted in a forum.
Thanks everybody in advance for your help.