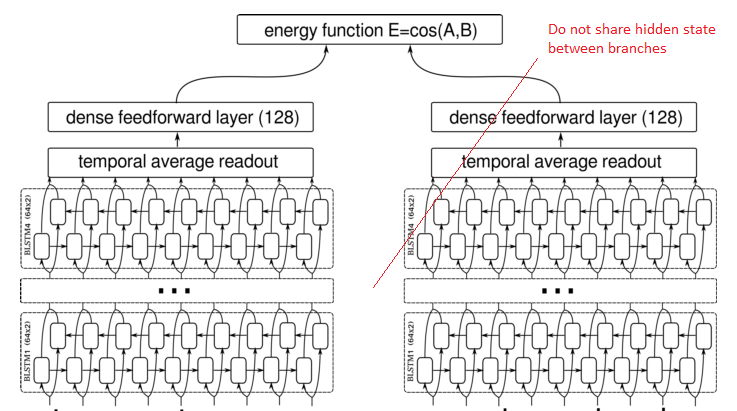
I am getting strange behavior during evaluation of a saimese network when I change the batch dimension of input data from whatever it is during training, to 1. After doing a forward pass with any batch_size > 1, the prediction shape for batch_sizes == 1 will be broadcast to the larger size.
Is there something I’m not understanding w.r.t. how pytorch handles different mini-batch inputs?
Thanks in advance.
eg
model = SaimeseNet(chars_size=chars, word_len=max_len,
embedding_dim=char_emb.shape[1], hidden_dim=15,
num_layers=2, out_dim=5)
model.eval()
var1 = Variable(test_inputs[:1])
var56 = Variable(test_inputs)
test_inputs.size()
>>> torch.Size([56, 42])
var56.size()
>>> torch.Size([56, 42]) # Batch_size x Max sequence length
var1.size()
>>> torch.Size([1, 42])
Doing a forward pass on these test datasets gives the following result. (actual output values not important).
model(var1, var1)
>>> Variable containing:
>>> 1.0000
>>> [torch.FloatTensor of size 1]
model(var56, var56)
>>> Variable containing:
>>> 1.0000
>>> 0.9999
>>> 0.9999
>>> 1.0000
>>> ....
>>> 1.0000
>>> [torch.FloatTensor of size 56]
# Call on batch_size=1 variable again
model(var1, var1)
>>> Variable containing:
>>> 1.0000
>>> 1.0000
>>> 1.0000
>>> 1.0000
>>> ....
>>> 1.0000
>>> [torch.FloatTensor of size 56]
class SaimeseNet(nn.Module):
def __init__(self, chars_size, word_len,
embedding_dim, hidden_dim, num_layers,
out_dim):
super(SaimeseNet, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.out_dim = out_dim
self.emb = nn.Embedding(chars_size, embedding_dim)
self.emb.weight = nn.Parameter(
torch.from_numpy(char_emb).type(torch.FloatTensor),
requires_grad=False)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers,
bidirectional=True, batch_first=True)
self.fc = nn.Linear(2 * self.hidden_dim, self.out_dim)
self.energy = nn.CosineSimilarity(dim=1)
self.hidden = self.init_hidden()
def init_hidden(self):
# Requires dim of (2, 1, hidden_dim) for bidirectional
return (Variable(torch.zeros(2 * self.num_layers, 1, self.hidden_dim)),
Variable(torch.zeros(2 * self.num_layers, 1, self.hidden_dim)))
def _forward_alg(self, inp):
x = self.emb(inp)
lstm_out, self.hidden = self.lstm(x, self.hidden)
# Average outputs across time
avg_lstm = torch.mean(lstm_out, dim=1)
# Fully connected layer
fc = self.fc(avg_lstm)
return fc
def forward(self, inp1, inp2):
x1 = self._forward_alg(inp1)
x2 = self._forward_alg(inp2)
energy = self.energy(x1, x2)
return energy