The picture below describes calculation of the local attention of Luong Attention.
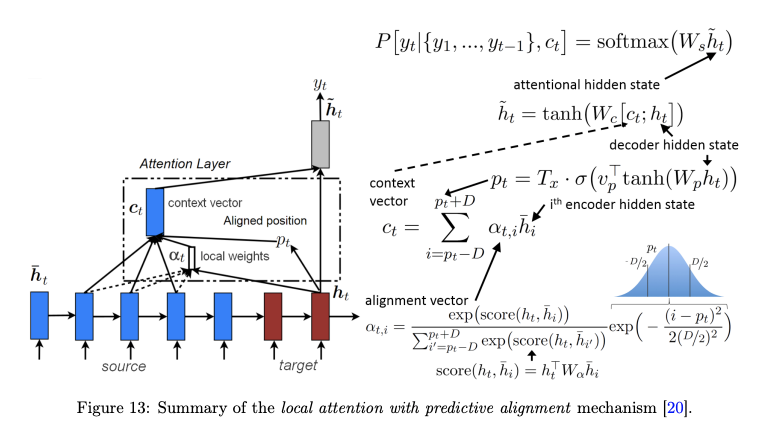
What I’m trying to do is getting the alignment vector in the picture. In the initializer of my decoder, I define v_p^T and W_p which are trainable weights like this:
self.attn_dim = hid_dim // 8
self.local_v = nn.Parameter(torch.randn(self.attn_dim, 1))
self.local_w = nn.Linear(hid_dim, self.attn_dim)
And then, I get alignment vector \alpha_{t, i} but the vector including all of range of the input sequence. Therefore, I need to sample it by (Pt + D, Pt - D) as showed in the picture.
align_score = self.attention(H, s) # [batch_size, 1, seq_len] # it should be [Batch_size, 1, 2D+1]
For the sampling, I need to get Pt. So I feed to the weights I defined in the initializer, and got Pt.
temp = self.local_w(s.unsqueeze(1)) # [Batch, 1, attn_dim]
Pt = Tx * torch.sigmoid(temp.bmm(self.local_v.repeat(batch_size, 1, 1))) # [Batch, 1, 1]
Pt is a tensor. I belive the elements in Pt are different each other, in every batch iteration. So the vector must be form of a tensor. However, at the same time, I also get align_score within the window [Pt-D, Pt+D] by using Pt tensor.
What I’m struggling is that the both conditions which is the grad must be flew into Pt (because of v_p and W_p), and which is the another condition that the Pt tensor should be utilized to getting index of the window within [Pt-D, Pt+D] should be satisfied at the same time. Can someone give me an advice? The entire code of calculating alignment score is shown below.
temp = self.local_w(s.unsqueeze(1)) # [Batch, 1, attn_dim]
Pt = Tx * torch.sigmoid(temp.bmm(self.local_v.repeat(batch_size, 1, 1))) # [Batch, 1, 1]
start = ??
end = ??
align_score = align_score[:, :, start:end] # [batch_size, 1, 2D + 1]
local = torch.tensor([x for x in range(1, align_score.size(2) + 1)]) # [2D + 1]
local = torch.exp(- ((local - Pt) ** 2)/((self.D ** 2) / 2)).view(1, 1, -1) # [2D + 1]
local = local.repeat(batch_size, 1, 1) # [B, 1, 2D + 1]
align_score = align_score * local # [B, 1, 2D + 1]
context = torch.bmm(align_score, H.permute(1, 0, 2)[:, start:end, :]) # [batch_size, 1, enc_hid]