Hey guys, I am loading datasets from Google Drive to colab. I have four classes and have 35000 images in first class, 11000 images in second class, 8000 images in third class and 26000 images in fourth class. I don’t think that having such a large dataset can be a problem. I then start training my dataset model using resnet101 in 30 epoch. After that no end, I have waited almost 2 hours about 3 times, but no result(GPU in Colab is on). Can any of you please help me why this is happening?
Hi,
This is a large computation for Google colab. There are some points in your training:
- Resnet 101 is a very deep model and in takes too much memory and power to be trained.
- GPUs on Google colab are shared on different VM instances, so you have only 16GB memory and a limited percentage of its power (Currently T4 GPU).
- I suggest to add a loss visualizer or print loss for every epoch and batch to see where you get stuck and what is gooing on. TensorboardX is available to help you through this.
Good luck
Hey, I have done that, the loss will print in every epoch, but printing first epoch is almost taking more than 1+ hour and still not printing. I am confused is there an problem with the code? Can you please tell any solution to this?
Actually, I have 2.1 million image to train on my code. As I told, Colab cannot support this amount of data. So I extracted a subsample of 2000 images, 200 for the test.
Next step, you have to make sure your model can overfit on this small train data. For this purpose, set high number of epochs. If your model can overfit, then you are good to go for your real dataset.
And let me explain a weird situation. I had implemented my code and started to overfit on a smaller data, but I got some syntax error in the library itself, not my code. So, after a lot of debugging, I found out, the problem was colab. The data did not flow in the CUDA cores and some dimensions of my matrices had been lost. So my suggestion is first make sure your model can overfit and if got any error, do not change you code, test it on another device.
Final point, You said you print your loss per epoch. It is huge amount of time, so print it batch by batch to make sure it is working.
1 Like
So, for my images, do you think I should take 1000 images from each class(I have four classes)? Then train it with CNN. Then over-fit it? By the way, how can I understand if it is overfitting the data? Sorry, I am not that expert in this field. Then after doing that overfit, what should I do exactly? Thank you.
Actually 1000 is an arbitrary number so you can choose what you want, even 100 images is enough sometimes.
Overfitting means your CNN network, learned only features in your samples not a generalization. It means you training loss should be very low, but if you test your trained model on a new unseen image, it will give you bad result (high loss value of test set).
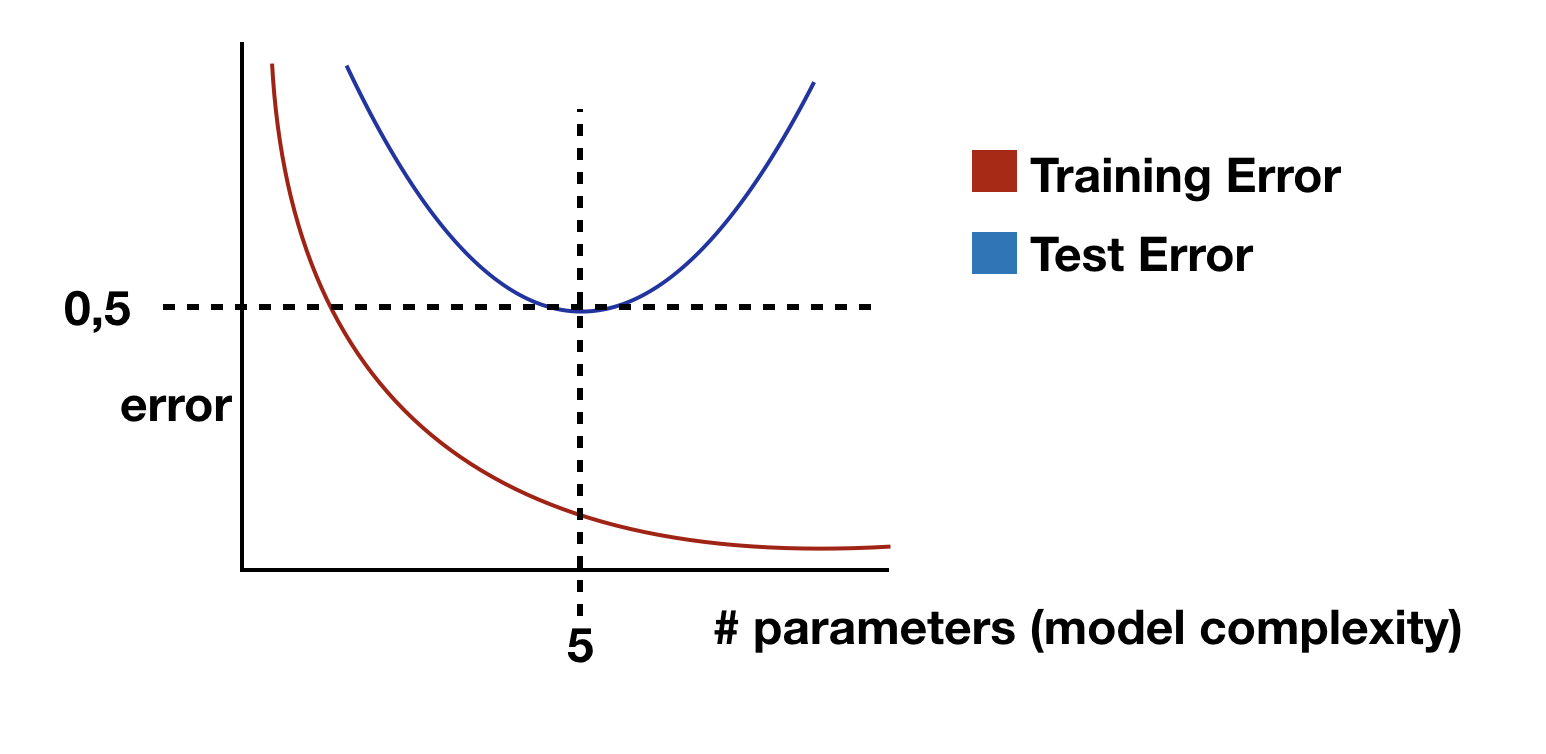
If your model can overfit, you model implementation is rational probably . Why we do this at all? Some times, you implement your model and it seem fine, but it cannot fit at all, even when you let it be trained for a big number of epochs.
If your model did not overfit, you should play with learning_rate, batch_size, learning_weight_decay, preprocessing, optimizers, other hyperparameters, etc.
A demonstration of overfitting can be like this: you train your model on 10 images for 100 epochs.
After making sure your model can be trained, you can proceed to test it on your real dataset.
Finally, I highly suggest to use tools like TensorboardX (interface of Tensorboard for Pytorch), Visdom, etc to visualize whats happening in each layer and each epoch. You can check what is happening on your gradients like vanishing or eexploding or even get your images from intermediate layers to make sure what is happening in your model.
In the end, many times, no one even experts cannot say what optimizer or what size of batch size, etc is good for a specific task. They get things done by experimenting many times. So the purpose of overfitting is to handle this problem.
By the way, I suggest for overfitting step, use Adam optimizer because it is more general and learns fast.
If you have any other questions, feel free to ask.
Good luck
1 Like
Sorry for the late reply, I have to go through once on Convolution Layers. So, in my case, I choose 1000 images from each class and 1000 epochs to train. So, I can do overfitting on this data. According to you, In many cases when we see that a model is fitting well, but there might be some fault that we can not see or just ignore, but can cause tremendous failure in the actual result, so overfitting can make sure that the dataset can properly fit on unseen data, right?
Also, I have never used learning_weight_decay, but studied it in theory, can you kindly show me some code, about how to do it with example? Also after how can I test on a real dataset? It has never trained on the whole dataset? Do you mean by I have to train 1000 images each time and train on 10 times as I have nearly 10000 images per class?
If it trains on a 1000 images, then for the rest 9000 images what should I do? Thanks in advance.
You’re welcome. Here are some points:
- 1000 epochs are too huge, consider numbers about 25 to 40 epochs. Actually, you have a few classes with a lot of examples, so you do not need a lot of time to train it even if you have deep model.
- If your model can fit properly, it is ok and you are good to go. No need for overfitting.
- Overfitting works as a precaution for you. For example, as you asked first in this thread, you are not sure your model working inefficient or colab is not working properly. So you use a small sample and train for longer time to make sure you have implemented everything (logical or optimization aspects) correctly.
- As I have mentioned before, we use experimental (fastest method by the way) configuration to make sure our model can overfit. For examples, using
Adamas optimizer orLeakyReLUas activation function. Many times, a simple mistake such as reading data inefficiently, unnecessary duplication of tensors, etc cause you lose a lot of your GPU memory. - Overfitting does not provice any confidence about your model. Actually, it works like a Counterexample.
6.Usinglearning_rate_decayis rare so you can check it after everything. Currently I do not have any useful example of this implementation but in a few days maybe I implement it myself. I will let you know if I implement it. - For last part, yes, 1000 image is enough and you do not need to include other image in this step, because we want to our model only learn a few things so can overfit.
In the end, if your model overfitted, you are good to go to use your real dataset. But still I am not sure Google colab can support it or not.
By the way, if this task important to you, you can rent a Google Preemptible compute engine or Amazon EC3 Spot which costs around 35$ per month for about 7 hours per day usage and a Tesla K80 GPU, Dual core CPU with 16 GB RAM.
1 Like