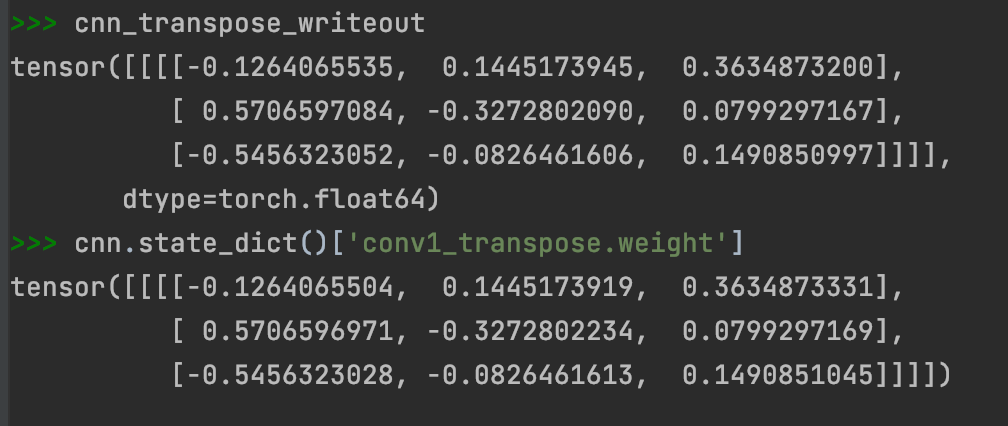
I think the difference comes from the usage of different dtypes. In the first print you can see that float64 is returned while the second tensor does not print the dtype so would be using the default float32 type, which has a reduced precision compared to float64.
Which type of model are you using that float64 is needed, as I haven’t seen such a use case before (besides some toy examples)?
Its a toy example to compare an implementation.
Everything is float 64 is in mine but I was curious if pytorch is doing things in float32.
Or perhaps it calls everything underneath in C and then maps it back to python. That communication layer between C and python might do some sort of compression. This is for the sake of increasing speeding of course
So in actual training performance is not affected (or maybe float64 is overkill)
The matrix below is the stored matrix in pytorch through the copy command. So after the copy it makes this minor modification.
Yes, by default, but you can also specify to use float64 if needed.
No, there is no compression involved and PyTorch will use the specified dtype.
I haven’t seen a ML/DL model, which “needs” float64 yet so the performance in the sense of model accuracy should not be affected. However, I would be interested to learn about such a model, which really needs 64 bits. The “speed” performance would be affected as you are not only using 2x the memory, but especially on the GPU would see a slowdown.
I was building my own transpose cnn for scratch and I noticed a tiny difference between mine and pytorch at roughly 10^-7 digits onwards, so I was just suprised.
I have been writing my stuff on CPU so I did not take into GPU issues.
Its mostly a learning experience for me. Nothing to report but I would be interested to check if float 64 might reduce iterations a bit in the training process (in gpu this would be at the cost of computational speed and probably not worth doing).