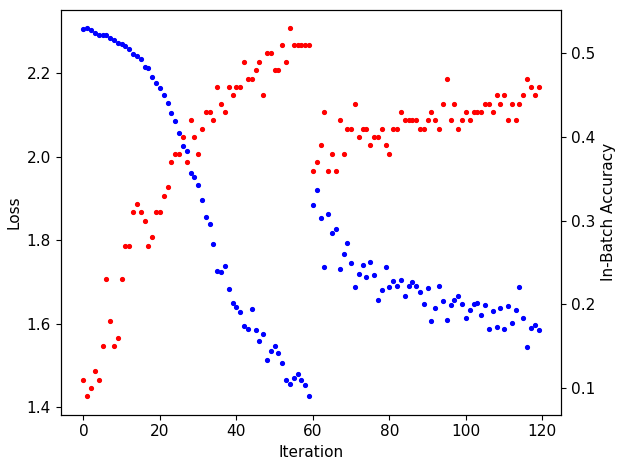
I’m training a CNN to predict digits using the MNIST database. I’m doing Data Augmentation and for some reason accuracy sharply decreases when advancing to the next epoch (iteration 60 in the image)
my_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomCrop((25,25)),
transforms.Resize((28,28)),
transforms.RandomRotation(degrees=45, fill=255),
transforms.RandomVerticalFlip(p=0.1),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])
dataset = MNISTDataset(transform = my_transforms)
train_loader = DataLoader(dataset = dataset, batch_size = 1000, shuffle=True)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.pool = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(10,20,kernel_size=5)
self.fc1 = nn.Linear(20*4*4, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self,x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1,20*4*4)
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=1)
return x
net = Net()
loss_function=nn.NLLLoss()
optimizer=optim.Adam(net.parameters())
EPOCHS=2
iteracion = 0
for epoch in range(EPOCHS):
for data in train_loader:
inputs, labels = data
inputs = inputs.view(-1,1,28,28)
net.zero_grad()
probabilities=net(inputs)
matches=[torch.argmax(i)==int(j) for i,j in zip(probabilities,labels)]
in_batch_acc=matches.count(True)/len(matches)
loss=loss_function(torch.log(probabilities), labels)
print('Loss:', round(float(loss), 3))
print('In-batch acc:', round(in_batch_acc, 2))
iteracion += 1
loss.backward()
optimizer.step()
@ptrblck instead of using my class MNISTDataset I used torchvision.datasets.MNIST and there’s not accuracy decline when advancing to next epoch. You’re right, so there’s a problem with my class MNISTDataset but I have no clue what could be. Maybe when advancing to next epoch transformations are applied again on the already transformed data? Here is the code of class MNISTDataset:
class MNISTDataset(Dataset):
def __init__ (self, transform = None):
xy = np.load('MNIST_train.npy', allow_pickle=True)
self.len = len(xy)
self.transform = transform
x = []
y = []
for i in xy:
x.append(i[0].reshape(28,28))
y.append(i[1])
x = np.array(x)/255
y = np.array(y)
self.x = torch.tensor(x, dtype=torch.float)
self.y = torch.tensor(y, dtype=torch.long)
def __getitem__(self, index):
if self.transform:
self.x[index] = self.transform(self.x[index])
return self.x[index], self.y[index]
def __len__(self):
return self.len
my_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomCrop((25,25)),
transforms.Resize((28,28)),
transforms.RandomRotation(degrees=45, fill=0),
transforms.RandomVerticalFlip(p=0.1),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])
dataset = MNISTDataset(transform = my_transforms)
train_loader = DataLoader(dataset = dataset, batch_size = 1000, shuffle=True)