In MultiHeadAttention, we perform linear projection to q,k,v and after that perform the attention operation.
The term inside the softmax (QK^T) can be decomposed as follows
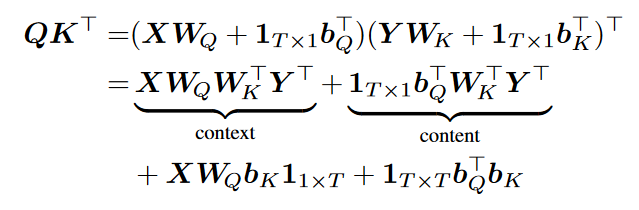
This means we can remove the projection for the key (and by doing so save parameters) and instead change the query projection to fit with key D_in (so instead of Wq being D_q_in * D_embed it will be D_q_in * D_k_in).
We can also use this to reduce the number of parameters for an already trained model, by swapping Wq by WqWk^T and Bq by BqWk^T.
the reason we don’t need the last 2 terms is because softmax(x+c) = softmax(x) and we do the softmax on the query dimension.
Am I missing something? Any input will be appreciated.
Thanks
*Images taken from https://arxiv.org/pdf/2006.16362.pdf - section 2.2