when I tried to use Dataparallel, I came across the problem" Arguments are located on different GPUs",I found that I should use the 0.5.0 version to solve the problem on the forum.
However ,I have been trying to find the correct version for a long time with no result.Can anyone help me ?
(ps, I tried to run the code on pytorch1.0, but error came in the dataloader part “RandomSampler’ object has no attribute 'replacement”.and I found no solution.
Thank you !!
1 Like
As far as i know there is no pytorch 0.5
Anyway that error means you have (probably) hardcoded model’s device inside the model itself
I am sorry that I didnt understand your answer.Do you mean that, after I use dataparallel to my model,I shouldnt use something like to.(device) inside the model?
Here is my error and code.I would appreciate it if you can have a look at it!
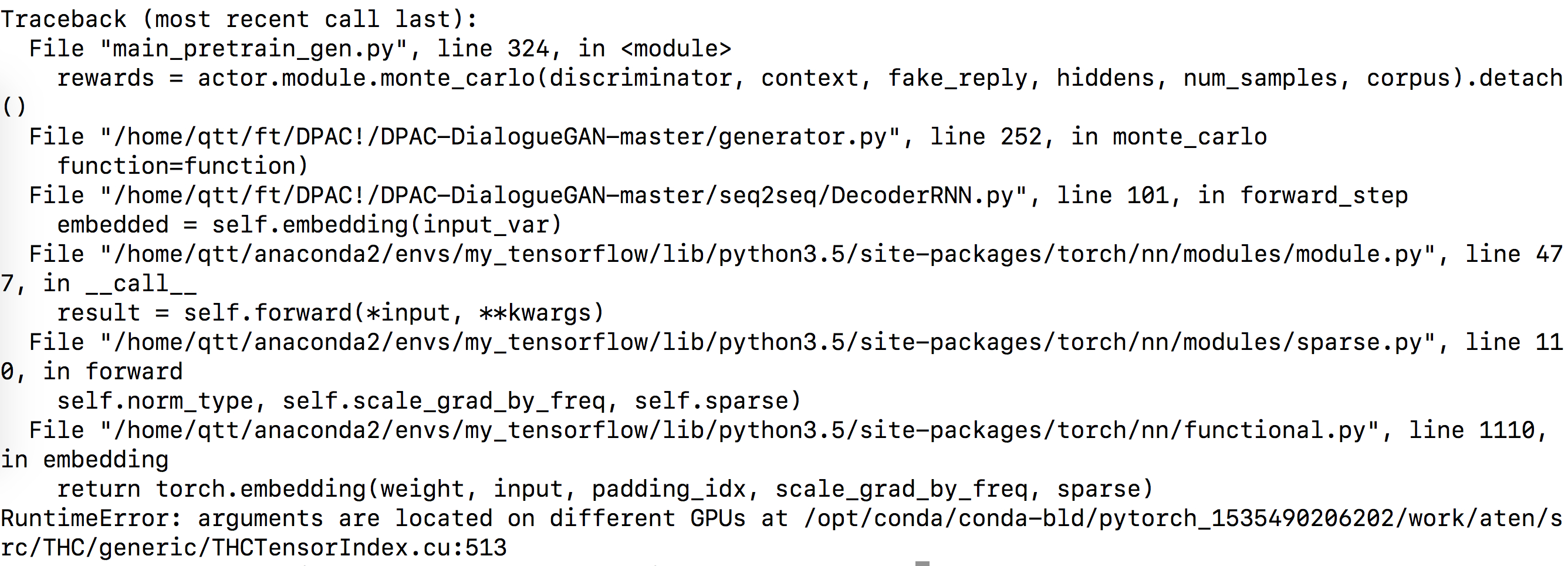
Hi,
I meant something like that yes. The problem is that when you set the model, dataparallel clones the model in each gpu dataparallel has access to.
Later on, if you hardcode a gpu in the forward function like x=x.to(‘cuda:0’), pytorch will allocate tensors in the wrong gpu.
Anyway this doesn’t look to be your case. It seems that your input is not allocated on the same gpu than your model. If you are not using dataparallel this probably means that you are allocating input and model on different gpus like
model = model.cuda() and input_var = input_var.cuda(1) if you are using dataparallel it’s more strange as the module should allocate inputs automatically (and you are not hardcoding it inside forward function).
Could you post how are you instantiating the model and applying dataparallel?
1 Like
That vey kind of you .I found that when I set the device I made a very stupid mistake.Now the code is running. I will see how it goes.
Thank you very much!!
hi, I found your toy code solution for the dataparallel problem.Your work is fantastic.
But when I immitated it on my own code, things went wrong.
it gave me RuntimeError: all tensors must be on devices[0]
Here is my Model_with_parallel:
class G_FullModel(nn.Module):
def __init__(self, actor, discriminator,g_loss):
super(G_FullModel, self).__init__()
self.G = actor
self.D = discriminator
self.loss = g_loss
def forward(self, targets, inputs, corpus):
fake_reply, word_probabilities, hiddens = G.sample(inputs, targets, TF=0)
num_samples = 3
rewards = G.monte_carlo(D, inputs, fake_reply, hiddens, num_samples,
corpus).detach()
pg_loss = loss(rewards, word_probabilities)
return torch.unsqueeze(pg_loss, 0), outputs
Here is how I used it:
G_model_parallel = G_FullModel(actor, discriminator, g_loss)
G_model_parallel = torch.nn.DataParallel(G_model_parallel, device_ids=[1, 2, 3],output_device=[1]).cuda()
context = context.to(device)
reply = reply.to(device)
loss, _ = G_model_parallel(reply, context, corpus)
Beg for your help!
I have tried to dataparallel my model and loss partly, the code could run.But still the GPU-Util on other gpus except device1 is almostly zero.
thank you very much!!
Hi, looks like here
torch.nn.DataParallel(G_model_parallel, device_ids=[1, 2, 3],output_device=[1]).cuda()
You are allocating the main device in cuda 0
To make it work you should set the same device for both output_device and main data parallel gpu
torch.nn.DataParallel(G_model_parallel, device_ids=[1, 2, 3],output_device=[1]).cuda(1)
thankyou very much! I will try and see how it works!
Hi,thanks for your help. sorry to bother you again.
A new problem came in my model, could you tell me to print something in the code to find where the bug exactly was?
the error was :
CuDNN error: CUDNN_STATUS_EXECUTION_FAILED

I was using dataparallel, when it went to compute reward,
def forward(self, targets, inputs, corpus):
fake_reply, word_probabilities, hiddens = self.G.sample(inputs, targets, TF=0)
num_samples = 3
rewards = self.G.monte_carlo(self.D, inputs, fake_reply, hiddens, num_samples, corpus).detach()
def monte_carlo(self, dis, context, reply, hiddens, num_samples, corpus):
# Initialize sample
batch_size = reply.size(0)
vocab_size = self.decoder.output_size
encoder_output, _ = self.encoder(context)
rewards = torch.zeros(self.max_len, num_samples, batch_size)
function = F.log_softmax
reply = reply
for t in range(self.max_len):
for n in range(num_samples):
samples = reply.clone()
hidden = hiddens[t]
output = reply[:, t]
# Pass through decoder and sample from resulting vocab distribution
for next_t in range(t + 1, self.max_len):
decoder_output, hidden, step_attn = self.decoder.forward_step(output.reshape(-1, 1).long(), hidden, encoder_output, function=function)
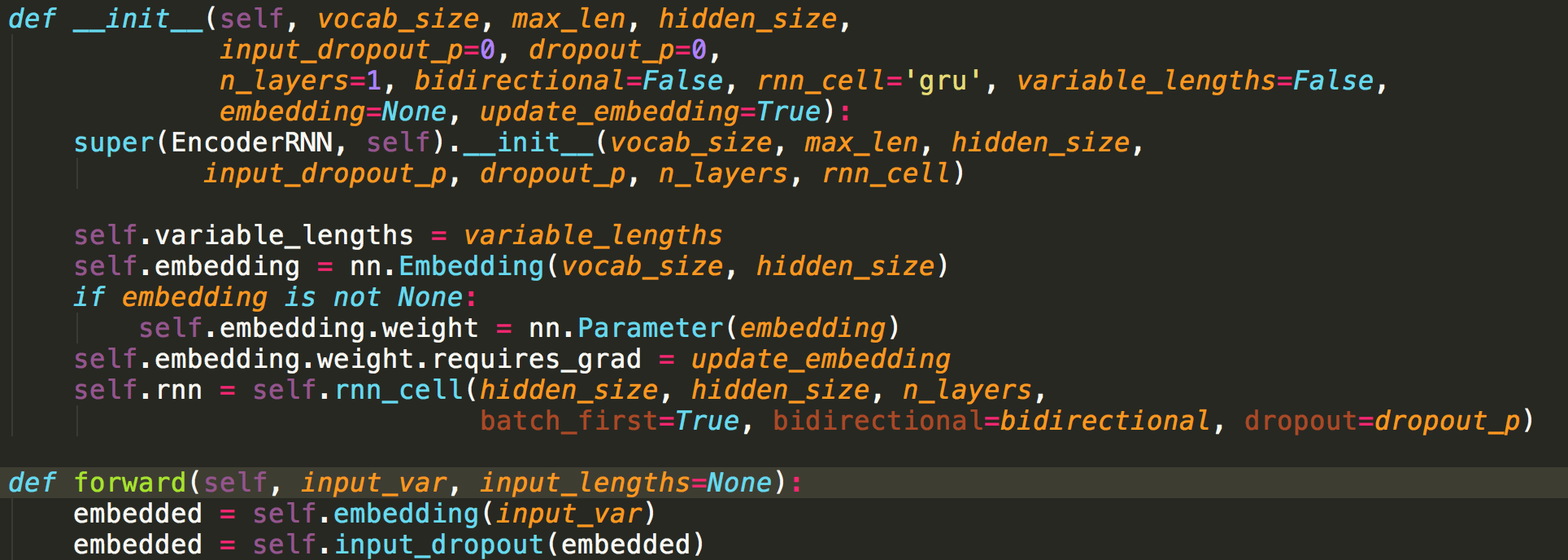
def forward_step(self, input_var, hidden, encoder_outputs, function):
batch_size = input_var.size(0)
output_size = input_var.size(1)
embedded = self.embedding(input_var)
embedded = self.input_dropout(embedded)
self.rnn.flatten_parameters()
output, hidden = self.rnn(embedded, hidden)
Here is other relevant code with forward_step:
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
rnn_cell='gru'
self.rnn = self.rnn_cell(hidden_size, hidden_size, n_layers, batch_first=True, dropout=dropout_p)
should I do something with the output and hidden in monte_carlo before I call the forward_step ?
or should print them to see where they are?
I tried printing embedded and embedded in forward_step function,they are distributed in devices(1,2,3).Then I got losted and have no way to debug,
Beg for your help!Thanks a lot!!
Hi, this is such a complex error.
Does it work without dataparallel?
Yes,
I googled the problem.The common answer is that put the relevant input and hidden on the right cuda . But here, everything is already in the parallel model that I shouldn’t assign them to specfic cuda.
Then I got confused…

Hmmm the think is that batches are distributed properly at the time of calling forward.
When you use dataparallel a copy of the model is created on each gpu and batch is distributed among them.
For example i see that inside montecarlo you have a reward variable initialized as zeros, but that reward is not properly allocated on its corresponding gpu.
Think that model parallel only allocates those variables which are defined before calling dataparallel. If you define a variable during the forward pass, you are the one in charge of allocating it in the proper gpu.
In the context of dataparallel, you have to softcode those variables allocating them into a device whose id depends on a variable or module device.
After reading your explanations, I want to ask you a few more details about the mechanism.
In the forward(the 1st func) func I defined, when the sample func is finished, where are the fake reply ,word_probabilities, hiddens . They are all summed and returned to device(1) or only the fake_reply are on device(1)? Should I do something before to the fake_reply, hiddens before I call the func monte_carlo?
I would appreciate it if your can reply for my confusion!
Everything computed inside forward will remain distributed among gpus. After returning forward’s output the batch is concatenated back in device 1.
The problem is that if you generate tensors inside the funcion, you have to prepare the code to make it device agnostic, such that every tensor you define inside the forward were properly allocated.
For example, inside forward, montecarlo, you are creating reward tensors initilized as zeros. That tensor is wrongly allocated in cpu. it requires something like torch.zeros().to(encoder_output.device)
In short, whatever coded inside forward is distributed
thank you very much for your clear interpretation.I will think and try more.
That’s very kind of you!
People talk about the version 0.4.1 here, when they write 0.5.0 (may be because 0.4.1 was after 0.4.0). I was confused too, but advice for “0.5.0” helps me when I switch to 0.4.1
Actually I think they’re talking of 1.0.0
For a long time it wasn’t clear if there was another release between 0.4.1 and 1.0.0 (which would have been 0.5) and this is why the master branch was set to version 0.5 although it was never officially released.
thank you very much~
thank you so much ,I will try the version 0.4.1:relaxed: