Thanks for your quick reply! 226 means nb_class = 226and so is 998. Value of target are the indexes range from 0 to nb_class which works fine when nb_class = 226 but triggers error when nb_class = 998. That’s the problem I meet.
This is wrong, as given in my previous post as the valid target class indices for 998 classes would be in the range [0, 997], which are representing 998 different values.
Yes you are right. But why did I trigger an error when I changenb_class from 226 to 998?
I don’t know why 226 classes were previously working, but you could iterate the dataset for an entire epoch and check the min. and max. target values. Maybe you had the same issue before, but no sample was using class index 226 previously.
Hello ptrblck!
When I increase my training set from 226 to 998, the dataloader locked and the program just stay there. When I click stop button, the ternimal shows that the code stop here:

I try to change num-workers = 0 but it doesn’t work. I can’t reduce the batch_size because that will impare the performance of my model.
Do you have any idea about this problem?
Could you calculate how much memory a batch of 998 samples would need and make sure your system is able to handle it? E.g. if you are running out of host RAM, the swap file might be used which could look like a “hang”.
Thank you for your reply. For my understanding, the number of samples dataloader process is only related to the batch size(which is locked to 16), so theoretically changing the training set from 226 to 998 should not require higher host RAM?
If you are lazily loading the samples, then yes, increasing the number of samples should increase the memory requirement by a small value. Otherwise, no as you would be preloading the data.
what you mean by “lazily loading”? I usetorch.utils.data.dataloader
Lazy loading refers to the Dataset implementation and is used if each sample if only loaded in the __getitem__ method (while e.g. the paths are stored in the __init__).
Since you are hitting the errors related to the dataset size I would still recommend to just check the memory usage and make sure the swap isn’t used.
Yes, you are right that memory usage is overflow. Are there any other choices except minimizing the size of training set?
You could use the described lazy loading approach (as is e.g. done in the ImageFolder implementation).
I.e. store the paths to your data in the Dataset.__init__ and load each sample in the Dataset.__getitem__. This tutorial gives you an example.
I just check my dataset code and found no differences from your given example(store path inDataset.__init__ and load data in Dataset.__getitem__ ). But it still meet the RAM limit and hang in there.
Here is my code:
Blockquote
class FVG(object):
def __init__(self,
data_root,
clip_len,
im_height,
im_width,
seed,
):
np.random.seed(seed)
self.is_train_data = True
self.data_root = data_root
self.clip_len = clip_len
self.im_height = im_height
self.im_width = im_width
self.transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((self.im_height, self.im_width)),
transforms.ToTensor()
])
self.im_shape = [self.clip_len, 3, self.im_height, self.im_width]
subjects = list(range(1, 226 + 1))
random.Random(1).shuffle(subjects)
subjects_augment = list(range(226 + 1, opt.num_train + 90 + 1))
random.Random(1).shuffle(subjects_augment)
self.train_subjects = subjects[:136] + subjects_augment
self.test_subjects = subjects[136:]
print('training_subjects', self.train_subjects, len(self.train_subjects))
print('testing_subjects', self.test_subjects, len(self.test_subjects))
def __getitem__(self, index):
"""
chose any two videos for the same subject
:param index:
:return:
"""
training_data_structure = {
'session1': list(range(1, 12 + 1)),
'session2': list(range(1, 9 + 1)),
'session3': list(range(1, 9 + 1)),
'train_all': list(range(1, 12 + 1)),
}
# 30 x 3 x 32 x 64
def random_si_idx():
if self.is_train_data:
si_idx = np.random.choice(self.train_subjects)
labels = self.train_subjects.index(si_idx)
else:
si_idx = np.random.choice(self.test_subjects)
labels = self.test_subjects.index(si_idx)
return si_idx, labels
def random_vi_idx(si):
if si in list(range(1, 147 + 1)):
if si in [1, 2, 4, 7, 8, 12, 13, 17, 31, 40, 48, 77]:
reading_dir = random.choice(['session1', 'session3'])
else:
reading_dir = 'session1'
elif si in list(range(147 + 1, 226 + 1)):
reading_dir = 'session2'
else:
reading_dir = 'train_all'
vi_idx = np.random.choice(training_data_structure[reading_dir])
return reading_dir, vi_idx
def random_length(dirt, length):
files = sorted(os.listdir(dirt))
num = len(files)
if num - length < 2:
return None
start = np.random.randint(1, num - length)
end = start + length
return files[start:end]
def read_frames(frames_pth, file_names):
# frames = np.zeros(self.im_shape, np.float32)
frames = []
for f in file_names:
frame = np.asarray(Image.open(os.path.join(frames_pth, f)))
frame = self.transform(frame)
frames.append(frame)
frames = torch.stack(frames)
return frames
si, labels = random_si_idx()
session_dir1, vi1 = random_vi_idx(si)
# print('Training data:', 'Reading', si, session_dir1, 'th subject:', vi1)
session_dir2, vi2 = random_vi_idx(si)
frames_pth1 = os.path.join(self.data_root, session_dir1, '%03d_%02d' % (si, vi1))
frames_pth2 = os.path.join(self.data_root, session_dir2, '%03d_%02d' % (si, vi2))
file_names1 = random_length(frames_pth1, self.clip_len)
file_names2 = random_length(frames_pth2, self.clip_len)
# print("training_data1:", session_dir1, '%03d_%02d' % (si, vi1))
# print("training_data2:", session_dir2, '%03d_%02d' % (si, vi2))
data1 = read_frames(frames_pth1, file_names1)
data2 = read_frames(frames_pth2, file_names2)
return data1, data2, labels
def __len__(self):
if self.is_train_data:
return len(self.train_subjects) * 12
else:
return len(self.test_subjects) * 12
That’s strange, since loading all images beforehand vs. lazily loading a batch of images should be visible in the memory usage.
I’m not familiar with your code, so you would need to profile the memory usage inside the Dataset to check where the memory allocation is coming from.
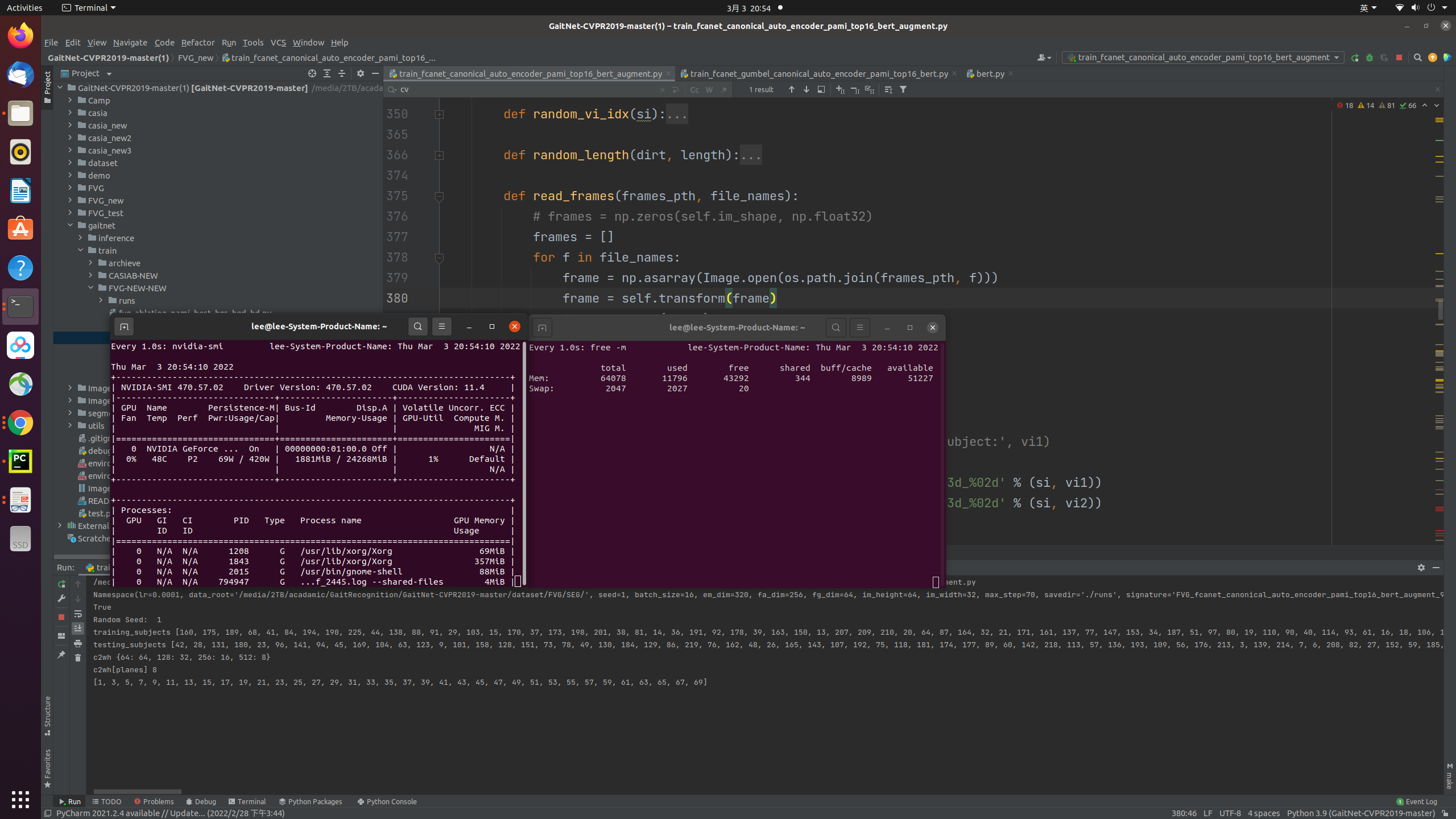
I found some other explaination and said the “hanging up” may occurred by the confliction of multithreading between pytorch and opencv. While I replace all the opencv package, the problem is still there. I just re-check the memory usage and here is the real-time screen shoot.
Hi,
I get this error when I’m on a multi GPU, when I’m on a mono GPU I don’t get it
I also use a segformer model , when I have my inputs on 3 channels I don’t get the error in both cases mono and multi GPU,
but when I’m on 5 channels I only get this error when I’m on a multi GPU.
…/aten/src/ATen/native/cuda/NLLLoss2d.cu:107: nll_loss2d_forward_kernel: block: [2,0,0], thread: [319,0,0] Assertion input_index >= 0 failed.
…/aten/src/ATen/native/cuda/NLLLoss2d.cu:104: nll_loss2d_forward_kernel: block: [13,0,0], thread: [288,0,0] Assertion t >= 0 && t < n_classes failed.
Did you check the output and target before passing them to the criterion as was already discussed in this thread?