Hi, I am debugging an implementation of DQN to play Pong-v0 in OpenAI gym. I have already used the same training paradigm and managed to solve CartPole-v0 with the maximum score (though the model did diverge shortly after achieving the max score in that environment) - I evaluated the model using an epsilon of 0.05 like in the original DQN paper. I am aware that training could be more stable with a target network but I really want to reproduce decent results with just one network for now.
I would really appreciate any insight someone could provide me as to what I may be doing wrong, thank you!
I am now dealing with learning from image data in the Pong environment using the following preprocessing.
preproc = transforms.Compose([
transforms.Grayscale(),
transforms.Resize([84,84]),
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
I train the model for 1 million frames using RMSProp and decay epsilon from 1->0.1 over 300,000 training steps. The model seems to just remain in the same general range for rewards. Even after epsilon reaches its minimum the training performance does not improve much. Evaluation score with eps=0.05 is relatively the same throughout training (about -5 in Pong). Additionally, the loss steadily increases to a very large magnitude (sometimes resulting in NaN gradients) to the order of 10^33 and above. This seems to be because the predicted Q Values explode over time, even with gradient clipping between [-1,1].
Example training graph:
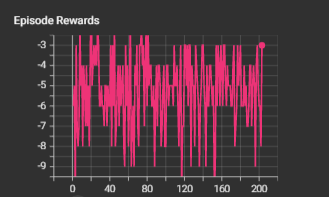
I was wondering whether my training code could be incorrect or be obstructing the graph in some way, the code below extracts the q values for the selected actions in each memory and computes the MSE loss wrt the discounted q value predicted from the policy network for the next state.
I have manually ensured that the following dimensions hold:
states = next_states = [BSx4x84x84] → grayscale states with 4 frames stacked
actions = terminal_mask = rewards = [BS] → action index, True/False terminal state, reward value for transition
model output = [BSx6] → Q value predictions
if t >= LEARNING_START and len(replay_buffer) >= BATCHSIZE:
training_steps += 1
states, actions, rewards, next_states, terminal_mask = replay_buffer.sample()
#if terminal state label is reward else reward + discounted Q estimate
with torch.no_grad():
ns_preds, ns_max_indices = torch.max(model(next_states.to(device)),dim=1)
rewards = rewards.to(device)
discounted_Q_estimates = rewards + GAMMA * ns_preds
y = torch.where(terminal_mask.to(device), rewards,
discounted_Q_estimates)
preds = model(states.to(device))
#get predicted q value for the relevant action, compare against label for estimated future reward
pred_q_vals = preds.gather(dim=1,
index=actions.unsqueeze(1).type(torch.int64).to(device)).squeeze(1)
optimizer.zero_grad()
error = criterion(pred_q_vals, y)
episode_running_loss.append(error.item())
error.backward()
#clamp grads
nn.utils.clip_grad_value_(model.parameters(), clip_value=1)
optimizer.step()