PyTorch autograd accumulates gradients, which can be used to increase effective batch size, for example, one can use following algorithm
- for each mini-batch from train_loader
- do forward and backward passes
- once every two iterations do:
optimizer.step()
optimizer.zero_grad()
This process will double the effective mini-batch size.
I have tested following two scenarios using above algorithm
Case 1:
mini_batch_size = 100
multi_batch_update = 4
- for each iteration:
- do forward and backward pass
- if iteration_number % 4 == 0:
-
scale down all parameter-gradients by factor of 4 -
optimizer.step() -
optmizer.zero_grad()
ie. above algorithm will allow 4 backward passes, so gradients are accumulated and once every 4 iteration optimizer will perform weight updates. The effective batch size this way is 400!
Case 2:
mini_batch_size = 200
multi_batch_update = 2
ie. we consider the exact same scenario but with minibatch of 200 and with weight updates after every 2 iterations (after scaling down all gradients by factor of 2), thus effective batch size is still 400.
However, both algorithms seem to follow different learning curve.
For example, I use algorithm from Case 1 for few iterations and then switch to Case 2 at about 4500th iteration, following is a learning curve
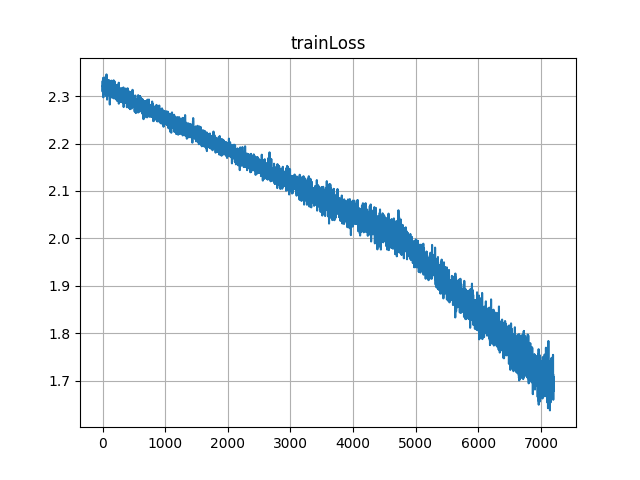
On the other hand if I start with Case 2 and then switch to Case 1 at about 2500th iteration, following is a learning curve
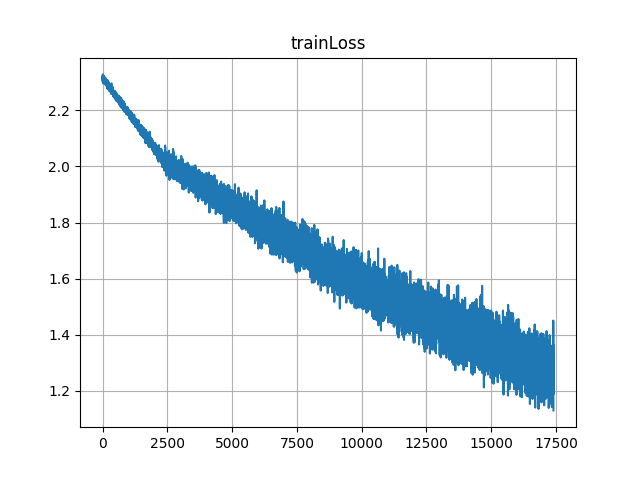
One can notice from learning curves that effective learning rate of Case 1 is lower than that for Case 2,
Can someone please explain this particular behaviour?
PS:
- I use Adam optimiser with default settings.
- Batchnorm is enabled (however, same behaviour is seen even without Batchnorm)
- Results are generated for fashionMnist dataset and can be reproduced with any simple CNN network.