Hi,
I have implemented the following architecture using pytorch.
I implemented the Grey block in the following loss function.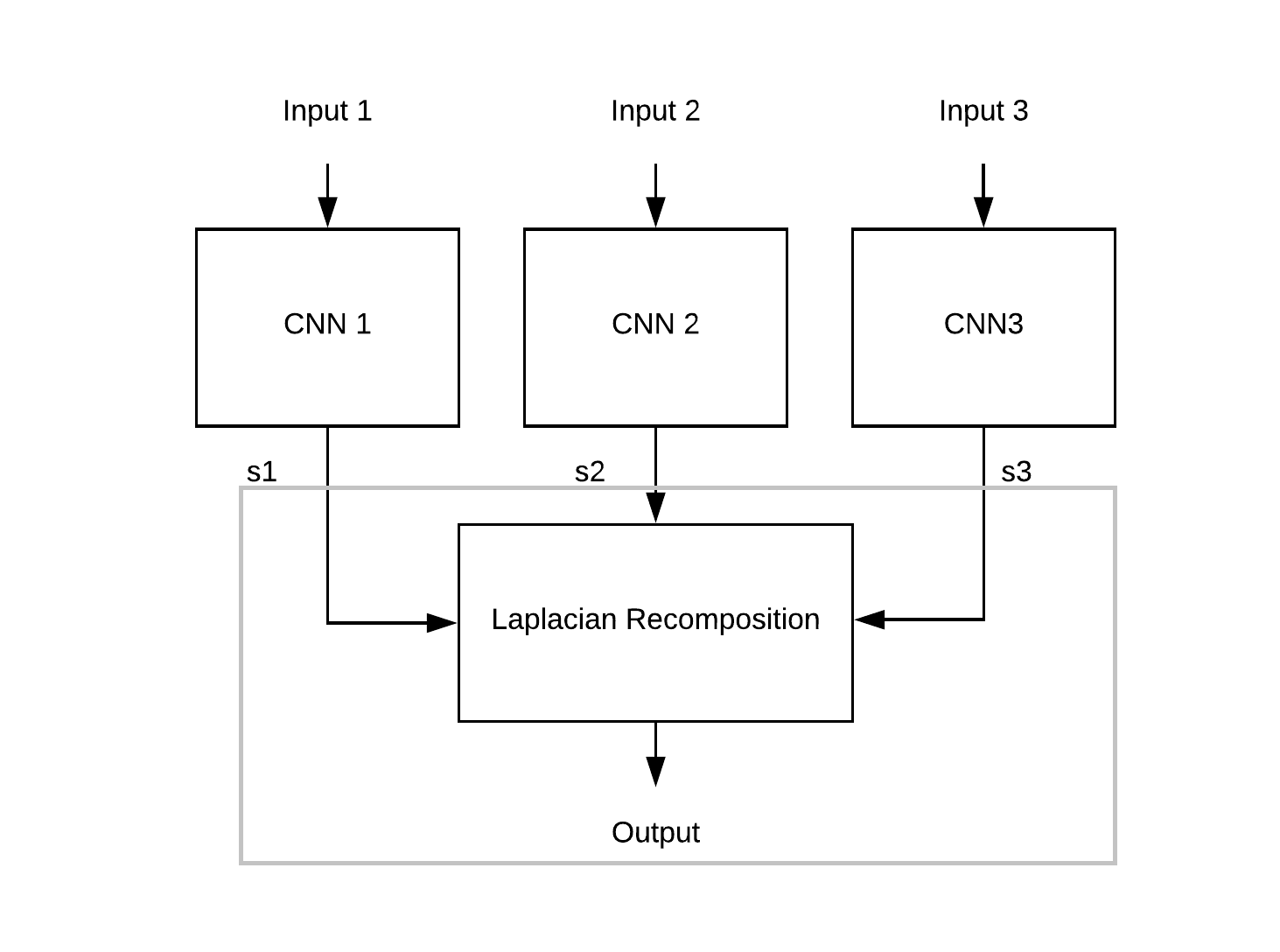
import torch
import torch.nn.functional as F
from torch.autograd import Variabledef _L1_loss(img1, img2, size_average = True):
L1_loss = (img1-img2).abs() size_average = True if size_average: return L1_loss.mean() else: return L1_loss.mean(1).mean(1).mean(1)class combined_loss(torch.nn.Module):
def __init__(self, window_size = 7, size_average = True): super(combined_loss, self).__init__() self.size_average = size_average self.channel = 1 self.kernelh = torch.tensor([[0.088, 0.3536, 0.5303, 0.3536, 0.0884]]) self.kernelv = torch.tensor([[0.088], [0.3536], [0.5303], [0.3536], [0.0884]]) def forward(self,s1, s2, lp, gt_img): kernelh = self.kernelh kernelh = kernelh.unsqueeze(dim=0).unsqueeze(dim=0) kernelh = kernelh.type_as(s1) kernelh = Variable(kernelh.cuda()) kernelv = self.kernelv kernelv = kernelv.unsqueeze(dim=0).unsqueeze(dim=0) kernelv = kernelv.type_as(s1) kernelv = Variable(kernelv.cuda()) w = torch.zeros([2, 2]) w[0, 0] = 1 w = w.type(torch.float32) w = Variable(w) w = w.cuda() stride = 2 # upsampling low pass residual lp_up = F.conv_transpose2d(lp, w.expand(lp.size(1), 1, 2, 2), stride=stride, groups=lp.size(1)) lp_up = torch.cat((lp_up[:,:,:,0:2],lp_up), dim=3) # padding columns lp_up = torch.cat((lp_up, lp_up[:,:,:,-2:]), dim=3) # padding columns lp_up = F.conv2d(lp_up, kernelh, padding = [0,0], groups = 1) # convolve in horizontal dimension lp_up = torch.cat((lp_up[:,:,0:2,:],lp_up), dim=2) # padding rows lp_up = torch.cat((lp_up, lp_up[:,:,-2:,:]), dim=2) # padding rows lp_up = F.conv2d(lp_up, kernelv, padding = [0,0], groups = 1) # convolve in vertical dimension s2 = lp_up + s2 # upsampling s2 s2_up = F.conv_transpose2d(s2, w.expand(s2.size(1), 1, 2, 2), stride=stride, groups=s2.size(1)) s2_up = torch.cat((s2_up[:,:,:,0:2],s2_up), dim=3) # padding columns s2_up = torch.cat((s2_up, s2_up[:,:,:,-2:]), dim=3) # padding columns s2_up = F.conv2d(s2_up, kernelh, padding = [0,0], groups = 1) # convolve in one dimension s2_up = torch.cat((s2_up[:,:,0:2,:],s2_up), dim=2) # padding rows s2_up = torch.cat((s2_up, s2_up[:,:,-2:,:]), dim=2) # padding rows s2_up = F.conv2d(s2_up, kernelv, padding = [0,0], groups = 1) # convolve in one dimension s1 = s2_up + s1 return _L1_loss(s1, gt_img, self.size_average)
When the code is run, it is expected to train all 3 CNNs. However the backpropagation does not seem to be happening as the loss does not change with epochs. I am new to pytorch and not able to resolve this. Any help will be appreciated.