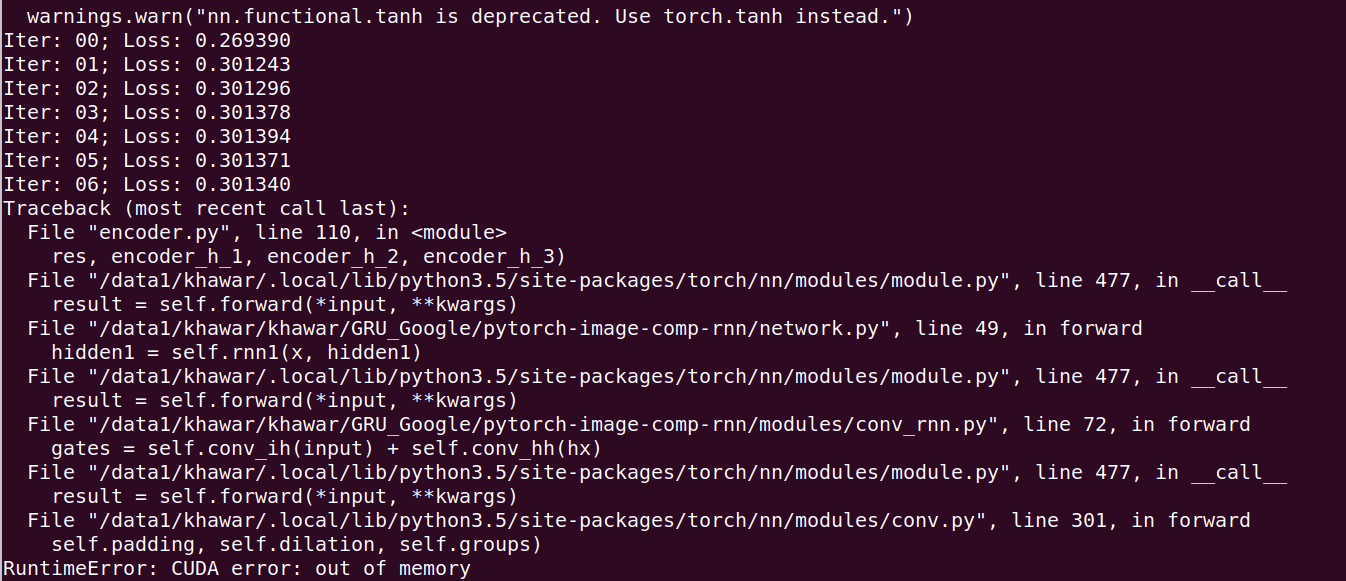
During training, the architecture generates three models and now encoder is used to encode images with iterations=16. After performing 6 iteration, i got an error. “CUDA out of memory”. I have 4 gpus and i also implemented dataparallel class but it does not work
Transformation while training
train_transform = transforms.Compose([
#transforms.RandomCrop((32, 32)),
transforms.ToPILImage(),
transforms.Resize((512, 512)),
#transforms.ColorJitter(brightness=0.5),
transforms.ToTensor(),
])
Encoder.py file
import argparse
import numpy as np
from scipy.misc import imread, imresize, imsave
import torch
from torch.autograd import Variable
parser = argparse.ArgumentParser()
parser.add_argument(
'--model', '-m', required=True, type=str, help='path to model')
parser.add_argument(
'--input', '-i', required=True, type=str, help='input image')
parser.add_argument(
'--output', '-o', required=True, type=str, help='output codes')
parser.add_argument('--cuda', '-g', action='store_true', help='enables cuda')
parser.add_argument(
'--iterations', type=int, default=16, help='unroll iterations')
args = parser.parse_args()
image = imread(args.input, mode='RGB')
image = torch.from_numpy(
np.expand_dims(
np.transpose(image.astype(np.float32) / 255.0, (2, 0, 1)), 0))
batch_size, input_channels, height, width = image.size()
assert height % 32 == 0 and width % 32 == 0
image = Variable(image, volatile=True)
torch.cuda.empty_cache()
import network
encoder = network.EncoderCell()
binarizer = network.Binarizer()
decoder = network.DecoderCell()
encoder.eval()
binarizer.eval()
decoder.eval()
print("Khawar", torch.cuda.current_device())
#torch.cuda.set_device(2)
#print("Khawar", torch.cuda.current_device())
encoder.load_state_dict(torch.load(args.model))
binarizer.load_state_dict(
torch.load(args.model.replace('encoder', 'binarizer')))
decoder.load_state_dict(torch.load(args.model.replace('encoder', 'decoder')))
encoder_h_1 = (Variable(
torch.zeros(batch_size, 256, height // 4, width // 4), volatile=True),
Variable(
torch.zeros(batch_size, 256, height // 4, width // 4),
volatile=True))
encoder_h_2 = (Variable(
torch.zeros(batch_size, 512, height // 8, width // 8), volatile=True),
Variable(
torch.zeros(batch_size, 512, height // 8, width // 8),
volatile=True))
encoder_h_3 = (Variable(
torch.zeros(batch_size, 512, height // 16, width // 16), volatile=True),
Variable(
torch.zeros(batch_size, 512, height // 16, width // 16),
volatile=True))
decoder_h_1 = (Variable(
torch.zeros(batch_size, 512, height // 16, width // 16), volatile=True),
Variable(
torch.zeros(batch_size, 512, height // 16, width // 16),
volatile=True))
decoder_h_2 = (Variable(
torch.zeros(batch_size, 512, height // 8, width // 8), volatile=True),
Variable(
torch.zeros(batch_size, 512, height // 8, width // 8),
volatile=True))
decoder_h_3 = (Variable(
torch.zeros(batch_size, 256, height // 4, width // 4), volatile=True),
Variable(
torch.zeros(batch_size, 256, height // 4, width // 4),
volatile=True))
decoder_h_4 = (Variable(
torch.zeros(batch_size, 128, height // 2, width // 2), volatile=True),
Variable(
torch.zeros(batch_size, 128, height // 2, width // 2),
volatile=True))
if args.cuda:
encoder = encoder.cuda()
binarizer = binarizer.cuda()
decoder = decoder.cuda()
image = image.cuda()
encoder_h_1 = (encoder_h_1[0].cuda(), encoder_h_1[1].cuda())
encoder_h_2 = (encoder_h_2[0].cuda(), encoder_h_2[1].cuda())
encoder_h_3 = (encoder_h_3[0].cuda(), encoder_h_3[1].cuda())
decoder_h_1 = (decoder_h_1[0].cuda(), decoder_h_1[1].cuda())
decoder_h_2 = (decoder_h_2[0].cuda(), decoder_h_2[1].cuda())
decoder_h_3 = (decoder_h_3[0].cuda(), decoder_h_3[1].cuda())
decoder_h_4 = (decoder_h_4[0].cuda(), decoder_h_4[1].cuda())
codes = []
res = image - 0.5
for iters in range(args.iterations):
encoded, encoder_h_1, encoder_h_2, encoder_h_3 = encoder(
res, encoder_h_1, encoder_h_2, encoder_h_3)
code = binarizer(encoded)
output, decoder_h_1, decoder_h_2, decoder_h_3, decoder_h_4 = decoder(
code, decoder_h_1, decoder_h_2, decoder_h_3, decoder_h_4)
res = res - output
codes.append(code.data.cpu().numpy())
print('Iter: {:02d}; Loss: {:.06f}'.format(iters, res.data.abs().mean()))
codes = (np.stack(codes).astype(np.int8) + 1) // 2
export = np.packbits(codes.reshape(-1))
np.savez_compressed(args.output, shape=codes.shape, codes=export)
Error image