It’s the first time I use PyTorch so I’d like to receive some feedback on whether I am doing things correctly. I have a model made of 3 different networks, each with its own set of parameters (theta1, theta2, theta3). The scheme below shows the architecture:
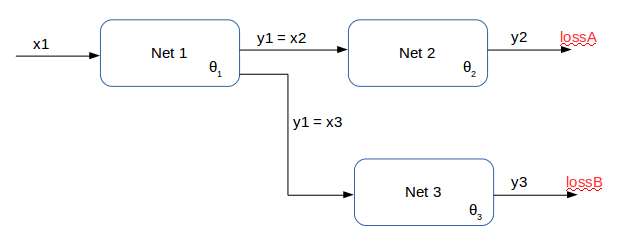
The training (supervised) of the model is carried out in two stages, which are iterated until convergence of all parameters. In the first stage, only net2 and net3 are trained, using respectively lossA and lossB. Thus I do the following (pseudocode):
#run forward pass of the model
[…]
lossA = nn.MSELoss(y2, y2_true)
lossB = nn.BCELoss(y3, y3_true_stage1)
net2_optimizer.zero_grad()
lossA.backward()
net2_optimizer.step() #update theta2
net3_optimizer.zero_grad()
lossB.backward()
net3_optimizer.step() #update theta3
In the second stage, only net1 is trained, using loss = lossA + lossB. However, lossB at this stage is different from lossB at stage1, because the same training examples are now given different labels (i.e. y3_true_stage2 != y3_true_stage1 for the same training examples). Thus in stage 2 I do:
lossA = nn.MSELoss(y2, y2_true)
lossB = nn.BCELoss(y3, y3_true_stage2)
loss = lossA + lossB
net1_optimizer.zero_grad()
loss.backward()
net1_optimizer.step() #update theta1
Do you think this code reflects correctly what I want to do, or there’s something that doesn’t match? Any feedback would be much appreciated. Thanks