I want to use the trained model in C++ with libtorch.
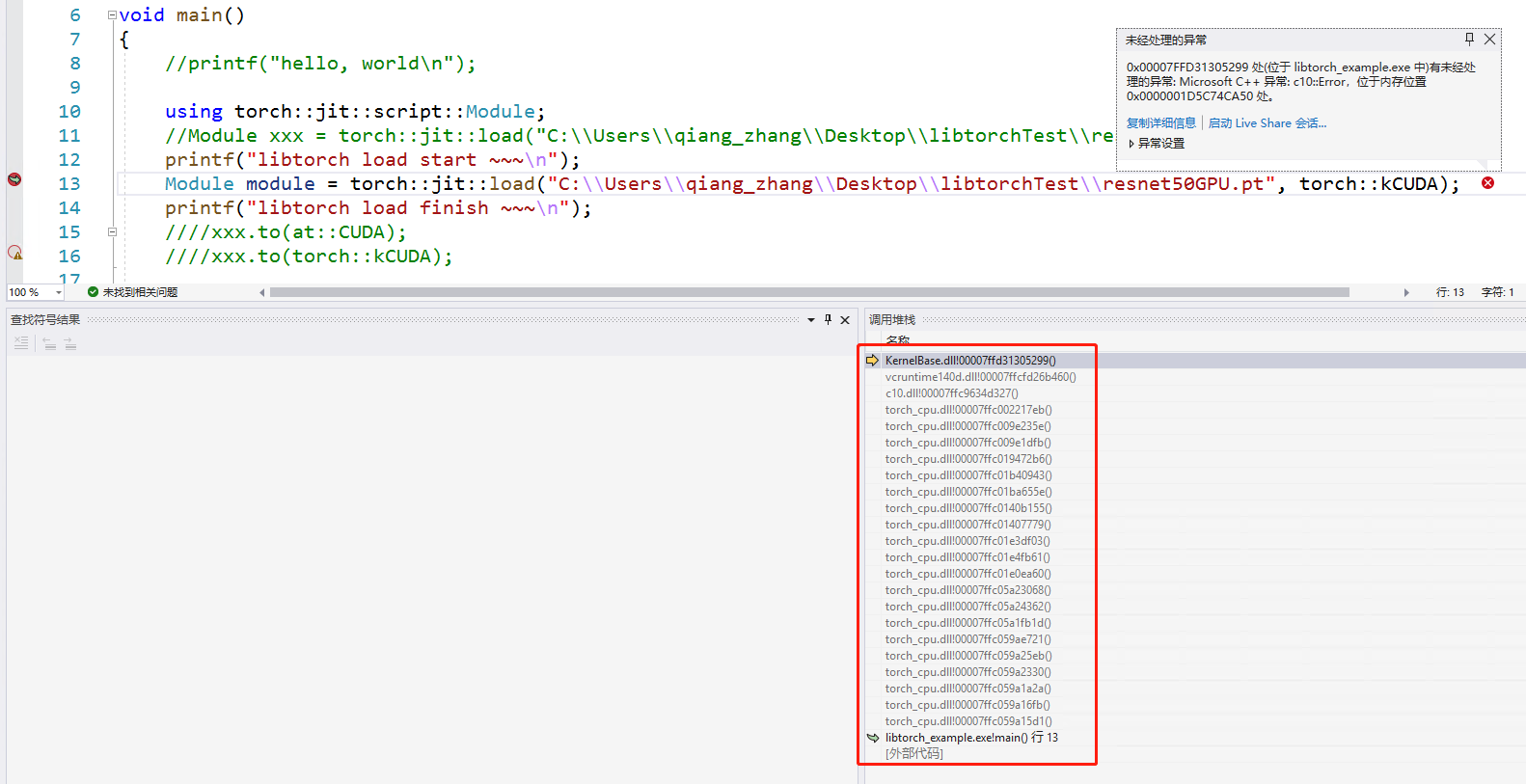
However, it failed when I want to load a gpu model
using torch::jit::script::Module;
Module module = torch::jit::load("resnetGPU.pt", torch::kCUDA);
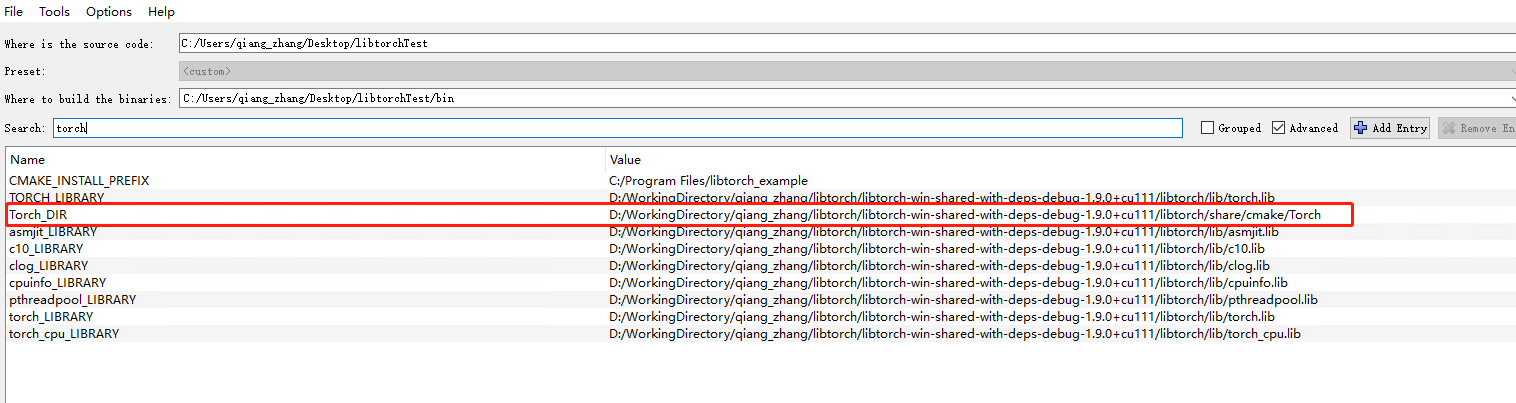
The gpu model is trained in linux, and the pytorch version is: 1.9.0+cu111, and the libtorch version is libtorch-win-shared-with-deps-debug-1.9.0+cu111.
The c++ project is built in win10, and the vs version is vs2022.
The code to generate the model is:
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True).cuda()
model=model.eval()
resnet = torch.jit.trace(model, torch.rand(1, 3, 224, 224).cuda())
resnet.save('resnetGPU.pt')
If we don’t want to assume that’s the source of the problem, the following are guesses:
CMake and find_package will only find the shared libraries during the build. PyTorch + CUDA also needs to be able to find the DLL files. I can’t think any simple ways I would recommend. You could copy the DLLs into the directory with the executable, but they’re huge.
Another thing to check would be if you’re building in DEBUG or RELEASE mode. If you’re building in release mode but have debug DLLs from PyTorch installed, that can cause issues. I ran into that once.
Not clear. As an aside, are you building with MinGW or MSVC? The libraries they produce are not compatible with each other. I don’t know if that’s a problem with DLLs, but if there are statically linked libraries getting used, that might be part of it.
What C++ debugging tools do you have available? It would be nice to step through the code or at least capture more than just an abort().