I’m trying to deploy the model at this link in a C++ crack segmentation application. I followed the steps at this link for converting the pytorch model and serializing it. Here is a link to the traced module. Also, this is a link to a sample image.
Here is the code at the original ‘inference_unet.py’ file:
import sys
import os
import numpy as np
from pathlib import Path
import cv2 as cv
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import torchvision.transforms as transforms
from unet.unet_transfer import UNet16, input_size
import matplotlib.pyplot as plt
import argparse
from os.path import join
from PIL import Image
import gc
from utils import load_unet_vgg16, load_unet_resnet_101, load_unet_resnet_34
from tqdm import tqdm
import torch #Hedeya
import torchvision #Hedeya
def evaluate_img(model, img):
input_width, input_height = input_size[0], input_size[1]
img_1 = cv.resize(img, (input_width, input_height), cv.INTER_AREA)
print(img_1.shape)
#X = train_tfms(Image.fromarray(img_1))
X = train_tfms(img_1)
print(X.shape)
X = Variable(X.unsqueeze(0)).cuda() # [N, 1, H, W]
print(X.shape)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing [Hedeya]
traced_script_module = torch.jit.trace(model, X) #Hedeya
traced_script_module.save("traced_unet-vgg16_model.pt") #Hedeya
mask = model(X)
print(mask.shape)
#mask = F.sigmoid(mask[0, 0]).data.cpu().numpy()
print(mask[0,0].shape)
mask = torch.sigmoid(mask[0, 0]).data.cpu().numpy() #Hedeya
mask = cv.resize(mask, (img_width, img_height), cv.INTER_AREA)
return mask
def evaluate_img_patch(model, img):
input_width, input_height = input_size[0], input_size[1]
img_height, img_width, img_channels = img.shape
if img_width < input_width or img_height < input_height:
return evaluate_img(model, img)
stride_ratio = 0.1
stride = int(input_width * stride_ratio)
normalization_map = np.zeros((img_height, img_width), dtype=np.int16)
patches = []
patch_locs = []
for y in range(0, img_height - input_height + 1, stride):
for x in range(0, img_width - input_width + 1, stride):
segment = img[y:y + input_height, x:x + input_width]
normalization_map[y:y + input_height, x:x + input_width] += 1
patches.append(segment)
patch_locs.append((x, y))
patches = np.array(patches)
if len(patch_locs) <= 0:
return None
preds = []
for i, patch in enumerate(patches):
patch_n = train_tfms(Image.fromarray(patch))
X = Variable(patch_n.unsqueeze(0)).cuda() # [N, 1, H, W]
masks_pred = model(X)
#mask = F.sigmoid(masks_pred[0, 0]).data.cpu().numpy()
mask = torch.sigmoid(masks_pred[0, 0]).data.cpu().numpy() #Hedeya
preds.append(mask)
probability_map = np.zeros((img_height, img_width), dtype=float)
for i, response in enumerate(preds):
coords = patch_locs[i]
probability_map[coords[1]:coords[1] + input_height, coords[0]:coords[0] + input_width] += response
return probability_map
def disable_axis():
plt.axis('off')
plt.gca().axes.get_xaxis().set_visible(False)
plt.gca().axes.get_yaxis().set_visible(False)
plt.gca().axes.get_xaxis().set_ticklabels([])
plt.gca().axes.get_yaxis().set_ticklabels([])
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-img_dir',type=str, help='input dataset directory')
parser.add_argument('-model_path', type=str, help='trained model path')
parser.add_argument('-model_type', type=str, choices=['vgg16', 'resnet101', 'resnet34'])
parser.add_argument('-out_viz_dir', type=str, default='', required=False, help='visualization output dir')
parser.add_argument('-out_pred_dir', type=str, default='', required=False, help='prediction output dir')
parser.add_argument('-threshold', type=float, default=0.2 , help='threshold to cut off crack response')
args = parser.parse_args()
if args.out_viz_dir != '':
os.makedirs(args.out_viz_dir, exist_ok=True)
for path in Path(args.out_viz_dir).glob('*.*'):
os.remove(str(path))
if args.out_pred_dir != '':
os.makedirs(args.out_pred_dir, exist_ok=True)
for path in Path(args.out_pred_dir).glob('*.*'):
os.remove(str(path))
if args.model_type == 'vgg16':
#model = load_unet_vgg16(args.model_path)
model = load_unet_vgg16(args.model_path, None) #Hedeya + None I/O False
elif args.model_type == 'resnet101':
model = load_unet_resnet_101(args.model_path)
elif args.model_type == 'resnet34':
model = load_unet_resnet_34(args.model_path)
print(model)
else:
print('undefind model name pattern')
exit()
channel_means = [0.485, 0.456, 0.406]
channel_stds = [0.229, 0.224, 0.225]
paths = [path for path in Path(args.img_dir).glob('*.*')]
for path in tqdm(paths):
#print(str(path))
train_tfms = transforms.Compose([transforms.ToTensor(), transforms.Normalize(channel_means, channel_stds)])
img_0 = Image.open(str(path))
img_0 = np.asarray(img_0)
if len(img_0.shape) != 3:
print(f'incorrect image shape: {path.name}{img_0.shape}')
continue
img_0 = img_0[:,:,:3]
img_height, img_width, img_channels = img_0.shape
prob_map_full = evaluate_img(model, img_0)
if args.out_pred_dir != '':
cv.imwrite(filename=join(args.out_pred_dir, f'{path.stem}.jpg'), img=(prob_map_full * 255).astype(np.uint8))
if args.out_viz_dir != '':
# plt.subplot(121)
# plt.imshow(img_0), plt.title(f'{img_0.shape}')
if img_0.shape[0] > 2000 or img_0.shape[1] > 2000:
img_1 = cv.resize(img_0, None, fx=0.2, fy=0.2, interpolation=cv.INTER_AREA)
else:
img_1 = img_0
# plt.subplot(122)
# plt.imshow(img_0), plt.title(f'{img_0.shape}')
# plt.show()
prob_map_patch = evaluate_img_patch(model, img_1)
#plt.title(f'name={path.stem}. \n cut-off threshold = {args.threshold}', fontsize=4)
prob_map_viz_patch = prob_map_patch.copy()
prob_map_viz_patch = prob_map_viz_patch/ prob_map_viz_patch.max()
prob_map_viz_patch[prob_map_viz_patch < args.threshold] = 0.0
fig = plt.figure()
st = fig.suptitle(f'name={path.stem} \n cut-off threshold = {args.threshold}', fontsize="x-large")
ax = fig.add_subplot(231)
ax.imshow(img_1)
ax = fig.add_subplot(232)
ax.imshow(prob_map_viz_patch)
ax = fig.add_subplot(233)
ax.imshow(img_1)
ax.imshow(prob_map_viz_patch, alpha=0.4)
prob_map_viz_full = prob_map_full.copy()
prob_map_viz_full[prob_map_viz_full < args.threshold] = 0.0
ax = fig.add_subplot(234)
ax.imshow(img_0)
ax = fig.add_subplot(235)
ax.imshow(prob_map_viz_full)
ax = fig.add_subplot(236)
ax.imshow(img_0)
ax.imshow(prob_map_viz_full, alpha=0.4)
plt.savefig(join(args.out_viz_dir, f'{path.stem}.jpg'), dpi=500)
plt.close('all')
gc.collect()
The following is the C++ code that I used to deploy the model using libtorch:
#include <torch/torch.h>
#include <iostream>
#include <torch/script.h>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
//#include <opencv2/dnn.hpp>
std::string get_image_type(const cv::Mat& img, bool more_info = true)
{
std::string r;
int type = img.type();
uchar depth = type & CV_MAT_DEPTH_MASK;
uchar chans = 1 + (type >> CV_CN_SHIFT);
switch (depth) {
case CV_8U: r = "8U"; break;
case CV_8S: r = "8S"; break;
case CV_16U: r = "16U"; break;
case CV_16S: r = "16S"; break;
case CV_32S: r = "32S"; break;
case CV_32F: r = "32F"; break;
case CV_64F: r = "64F"; break;
default: r = "User"; break;
}
r += "C";
r += (chans + '0');
if (more_info)
std::cout << "depth: " << img.depth() << " channels: " << img.channels() << std::endl;
return r;
}
void show_image(cv::Mat& img, std::string title)
{
std::string image_type = get_image_type(img);
cv::namedWindow(title + " type:" + image_type, cv::WINDOW_NORMAL); // Create a window for display.
cv::imshow(title, img);
cv::waitKey(0);
}
auto transpose(torch::Tensor tensor, c10::IntArrayRef dims = { 0, 3, 1, 2 })
{
std::cout << "############### transpose ############" << std::endl;
std::cout << "shape before : " << tensor.sizes() << std::endl;
tensor = tensor.permute(dims);
std::cout << "shape after : " << tensor.sizes() << std::endl;
std::cout << "######################################" << std::endl;
return tensor;
}
auto ToTensor(cv::Mat img, bool show_output = false, bool unsqueeze = false, int unsqueeze_dim = 0)
{
std::cout << "image shape: " << img.size() << std::endl;
torch::Tensor tensor_image = torch::from_blob(img.data, { img.rows, img.cols, 3 }, torch::kByte);
if (unsqueeze)
{
tensor_image.unsqueeze_(unsqueeze_dim);
std::cout << "tensors new shape: " << tensor_image.sizes() << std::endl;
}
if (show_output)
{
std::cout << tensor_image.slice(2, 0, 1) << std::endl;
}
std::cout << "tenor shape: " << tensor_image.sizes() << std::endl;
return tensor_image;
}
auto ToInput(torch::Tensor tensor_image)
{
// Create a vector of inputs.
return std::vector<torch::jit::IValue>{tensor_image};
}
auto ToCvImage(torch::Tensor tensor)
{
int width = tensor.sizes()[0];
int height = tensor.sizes()[1];
try
{
cv::Mat output_mat(cv::Size{ height, width }, CV_8UC3, tensor.data_ptr<uchar>());
show_image(output_mat, "converted image from tensor");
return output_mat.clone();
}
catch (const c10::Error& e)
{
std::cout << "an error has occured : " << e.msg() << std::endl;
}
return cv::Mat(height, width, CV_8UC3);
}
int main() {
cv::Mat img = cv::imread("D:/Post_Grad/STDF/crack_segmentation-master_original/test_images_mine/00526.jpg");
cv::Mat img_1;
cv::resize(img, img_1, cv::Size(448, 448), 0, 0, cv::INTER_AREA);
show_image(img_1, "Test Image");
// convert the cvimage into tensor
auto tensor = ToTensor(img_1);
std::cout << "To Tensor: " << tensor.sizes() << std::endl;
auto cv_img = ToCvImage(tensor);
show_image(cv_img, "converted image from tensor");
// swap axis
tensor = transpose(tensor, { (2),(0),(1) });
std::cout << "transpose: " << tensor.sizes() << std::endl;
// convert the tensor into float and scale it
tensor = tensor.toType(c10::kFloat).div(255);
//normalize
tensor[0] = tensor[0].sub_(0.485).div_(0.229);
tensor[1] = tensor[1].sub_(0.456).div_(0.224);
tensor[2] = tensor[2].sub_(0.406).div_(0.225);
//add batch dim (an inplace operation just like in pytorch)
tensor.unsqueeze_(0);
tensor = tensor.to(torch::kCUDA);
std::cout << "unsqueeze: " << tensor.sizes() << std::endl;
auto input_to_net = ToInput(tensor);
torch::jit::script::Module module;
try
{
// Deserialize the ScriptModule from a file using torch::jit::load().
module = torch::jit::load("D:/Post_Grad/STDF/crack_segmentation-master_original/traced_unet-vgg16_model.pt");
// Execute the model and turn its output into a tensor.
torch::Tensor output = module.forward(input_to_net).toTensor();
//sizes() gives shape.
std::cout << output.sizes() << std::endl;
//std::cout << "output: " << output[0] << std::endl;
//std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';
output = torch::sigmoid(output);
auto out_tensor = output.squeeze(0).detach().permute({ 1, 2, 0 });
//auto out_tensor = output.squeeze().detach();
std::cout << "out_tensor (after squeeze & detach): " << out_tensor.sizes() << std::endl;
out_tensor = out_tensor.mul(255).clamp(0, 255).to(torch::kU8);
out_tensor = out_tensor.to(torch::kCPU);
cv::Mat resultImg(448, 448, CV_8UC3);
std::memcpy((void*)resultImg.data, out_tensor.data_ptr(), sizeof(torch::kU8) * out_tensor.numel());
cv::resize(resultImg, resultImg, cv::Size(1280, 720), 0, 0, cv::INTER_AREA);
cv::imwrite("D:/Post_Grad/STDF/crack_segmentation-master_original/test_images_mine/00526-seg-2.jpg", resultImg);
}
catch (const c10::Error& e)
{
std::cerr << "error loading the model\n" << e.msg();
std::system("pause");
return -1;
}
std::cout << "ok\n";
std::system("pause");
return 0;
//std::cin.get();
}
The output from the original pytorch model is as follows:
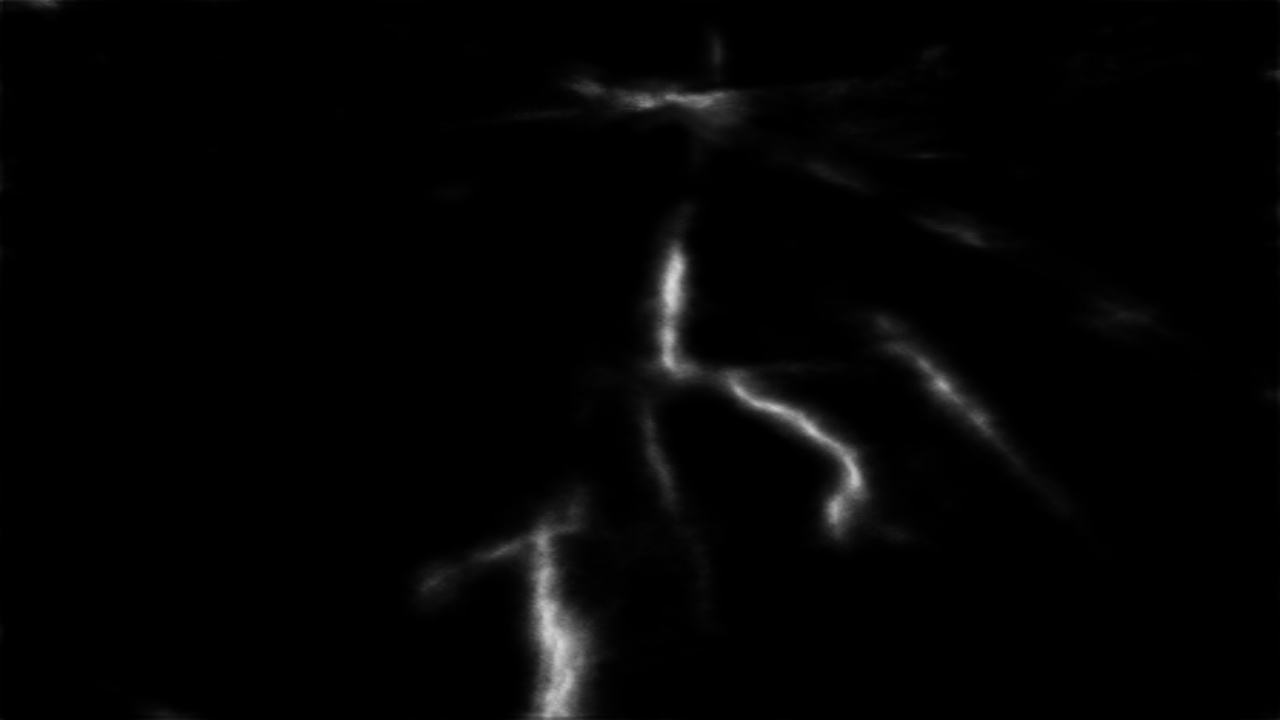
The output from the libtorch code is as follows:

It looks similar to the output from pytoch, but it’s repeated 3 times beside each other.
I failed to discover the reason for this mistake in the above C++. Pls help to check and advise.