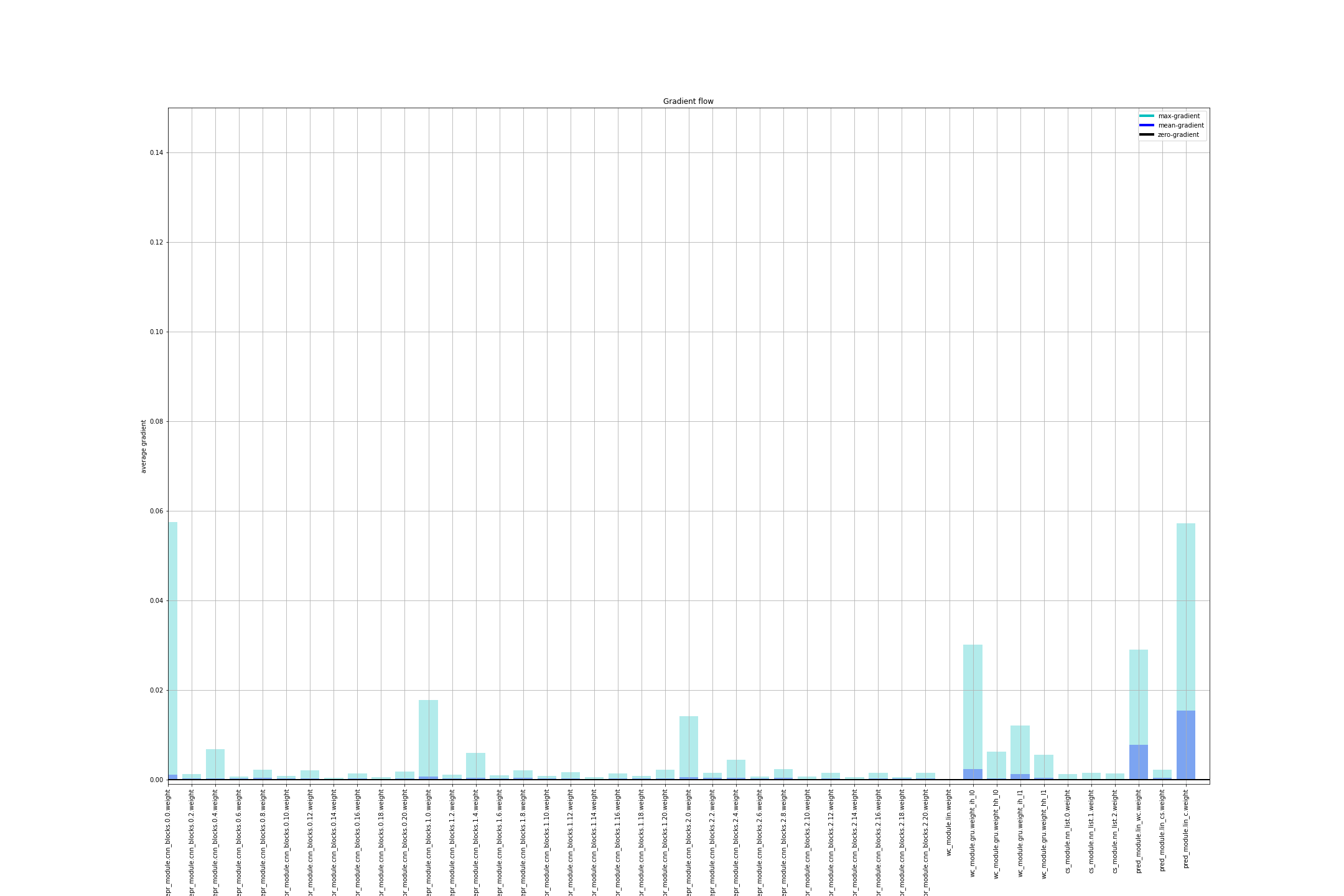
Hello,
I’ve been implementing a data fusion model, and it mostly works, but in one of the modules I am having trouble with the parameters of a linear layer not updating. I’m guessing it’s something in my intermediate calculations, but I can’t seem to figure out what.
Here is my init and forward implementation:
class WeightedCombinationModule(nn.Module):
def __init__(self, in_size, pool_size, hidden_size=64,
rnn_layers=2, dropout=0.7, a=9.0, b=0.01, c=10.0):
super(WeightedCombinationModule, self).__init__()
# create class variables
self.__dict__.update(locals())
# pooling layer
self.Pool = nn.MaxPool2d((1, self.pool_size), self.pool_size//2)
# quality weight parameters
wc_h = 1
wc_w = (self.in_size[-1] - (self.pool_size-1)-1) // (self.pool_size//2) + 1
self.lin = nn.Linear(wc_h*wc_w*in_size[1], 1)
# RNN
self.gru = nn.GRU(wc_w, self.hidden_size, self.rnn_layers, batch_first=True)
def forward(self, Sn):
Fn = torch.stack([self.Pool(s.squeeze(1)) for s in Sn.split(1,1)], 1)
# encoding vector
un = torch.flatten(Fn, 2, 4)
# quality weights
inter = self.lin(un).squeeze(2)
en = torch.div(inter, un.size(2))
a_tildas = self.a / (1+torch.exp(-en/self.b)) + self.c
a_sum = torch.sum(a_tildas, 1)
alphas = a_tildas / a_sum.unsqueeze(1)
a_temp = alphas.view(*alphas.size(), 1, 1, 1)
C = a_temp * Fn
C = torch.sum(C, 1).squeeze(2)
# rnn
output, _ = self.gru(C) # (batch, seq-len, hidden-size)
r_wc = output.sum(2) # (batch, seq-len)
return r_wc
Edit: For clarity, here is a sample of one step’s gradients. You can see that the params of the linear layer have no gradient for some reason.