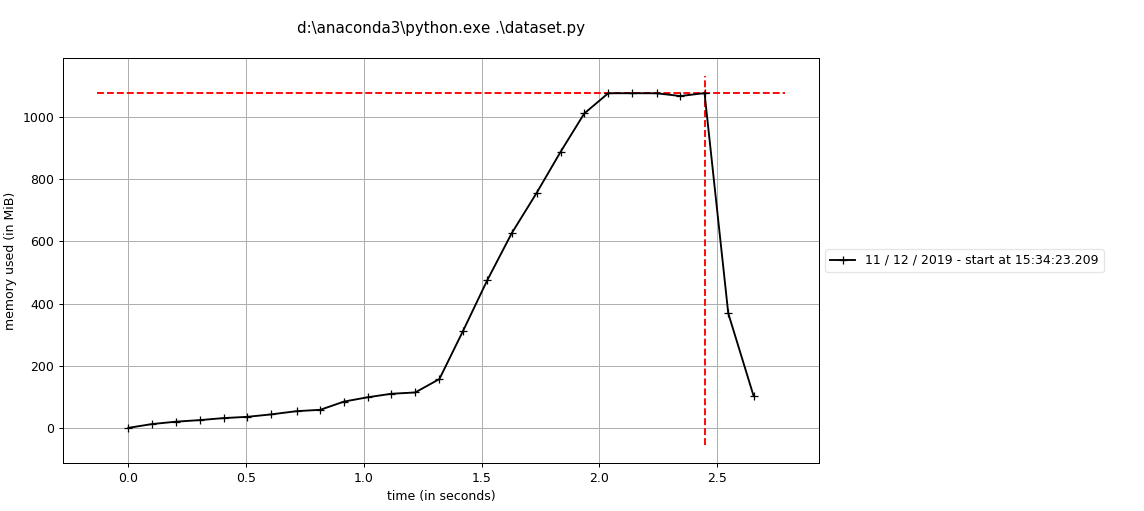
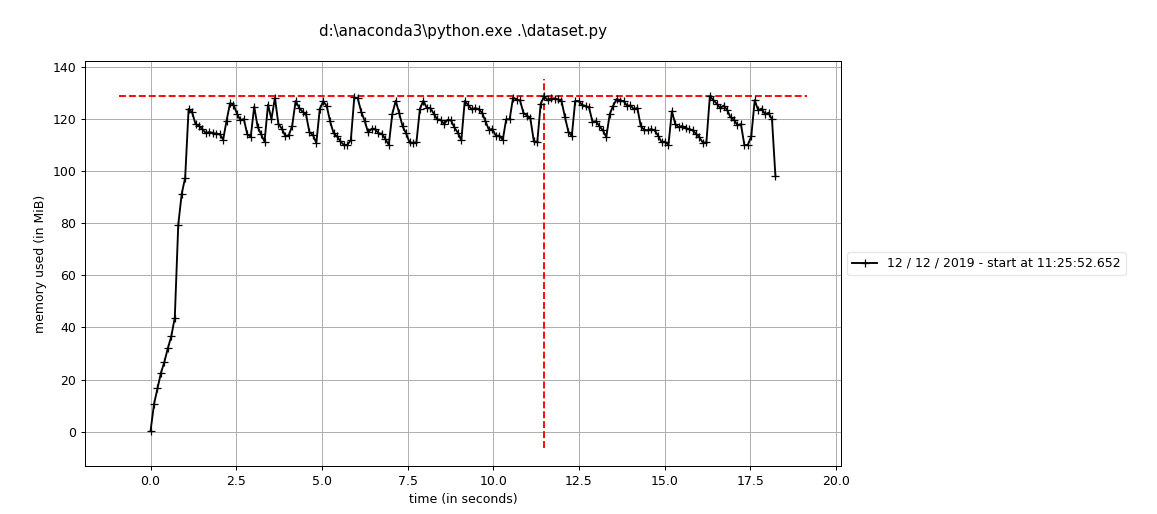
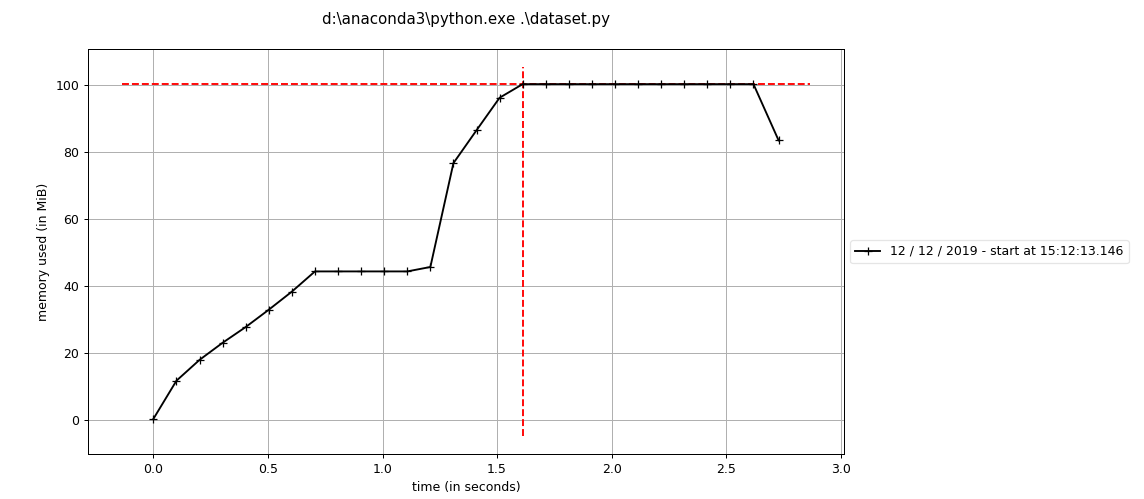
Hi @apaszke, I use same way to load 1K+ files via dataloader, so each dataloader __getindex__ will return one file, however, I always get error like
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 90300) is killed by signal: Killed.
seems each worker in data loader has either memory or time limit? if we put some parsing logic there(in our case we read parquet file), it will break?
I have checked the the source code for dataloader, basically we could set a timeout
def _try_get_data(self, timeout=_utils.MP_STATUS_CHECK_INTERVAL):
# Tries to fetch data from `self._data_queue` once for a given timeout.
# This can also be used as inner loop of fetching without timeout, with
# the sender status as the loop condition.
#
# This raises a `RuntimeError` if any worker died expectedly. This error
# can come from either the SIGCHLD handler in `_utils/signal_handling.py`
# (only for non-Windows platforms), or the manual check below on errors
# and timeouts.
#
# Returns a 2-tuple:
# (bool: whether successfully get data, any: data if successful else None)
try:
data = self._data_queue.get(timeout=timeout)
the default is 5s,
MP_STATUS_CHECK_INTERVAL = 5.0
r"""Interval (in seconds) to check status of processes to avoid hanging in
multiprocessing data loading. This is mainly used in getting data from
another process, in which case we need to periodically check whether the
sender is alive to prevent hanging."""
what is this interval means? I try to increase timeout in multi worker definition but get same error. only difference is final error msg will be like
RuntimeError: DataLoader worker (pid 320) is killed by signal: Segmentation fault.