For the network such as SSD, there is only one output layer. So the loss is calculated by the loss function, and loss.backward() is then used to calculate gradients of each layer from the output layer.However, for the network such as RetinaNet which utilizes FPN structure, there are multiple output layers.
And in https://github.com/kuangliu/pytorchretinanet/blob/2d7c663350f330a34771a8fa6a4f37a2baa52a1d/
train.py#L75 . The losses from multiple output layers are added up, and the loss.backward() is used based on the total loss.
So, my question is why the loss should be added up beform loss.backward() rather than loss1.backward(), loss2.backward()… for each output layer respectively?
Since the gradients will be accumulated for each backward pass, it should be the same.
Here is a very simple example:
torch.manual_seed(2809)
model = nn.Linear(10, 2)
x = torch.randn(1, 10)
target1 = torch.randn(1, 2)
target2 = torch.empty(1, dtype=torch.long).random_(2)
criterion1 = nn.MSELoss()
criterion2 = nn.NLLLoss()
output = model(x)
loss1 = criterion1(output, target1)
loss2 = criterion2(F.log_softmax(output, 1), target2)
loss1.backward(retain_graph=True)
loss2.backward()
print(model.weight.grad)
# Sum losses
torch.manual_seed(2809)
model = nn.Linear(10, 2)
x = torch.randn(1, 10)
target1 = torch.randn(1, 2)
target2 = torch.empty(1, dtype=torch.long).random_(2)
criterion1 = nn.MSELoss()
criterion2 = nn.NLLLoss()
loss1 = criterion1(model(x), target1)
loss2 = criterion2(F.log_softmax(model(x), 1), target2)
loss = loss1 + loss2
loss.backward()
print(model.weight.grad)
I think it’s better performance-wise as you will just call backward once.
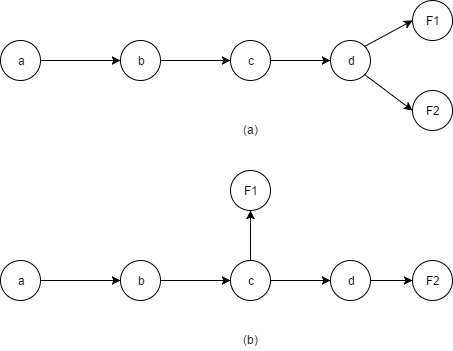
Thank you for the reply. The code provided is like (a) in the picture(F1 == loss1 and F2 == loss2), will it be same for (b)? if so, could you please tell me where and how the information of grad has been saved and used in pytorch?
For each trainable parameter, the gradient is accumulated/added up in its .grad buffer (for example, conv.weight.grad, conv.bias.grad) and later used by the optimizer (such as Adam, SGD) for gradient descent.