I’m running some experiments on Pytorch, with very simple settings, and simple I.I.D data of MNIST
criterion: torch.nn.CrossEntropyLoss
optimizer: torch.optim.SGD
on the model:
class MNIST_Net(nn.Module):
def __init__(self, name, in_channels, hidden_channels, num_hiddens, num_classes):
super(MNIST_Net, self).__init__()
self.name = name
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim = 1)
and the model update snipper
for _ in range(self.local_epoch):
for data, labels in self.dataloader:
data, labels = data.float().to(self.device, non_blocking=True), labels.long().to(self.device,non_blocking=True)
optimizer.zero_grad()
outputs = self.model(data)
loss = eval(self.criterion)()(outputs, labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 5)
optimizer.step()
if self.device == "cuda": torch.cuda.empty_cache()
The code works properly when I used device = torch.device('cpu')
but when I switch it to device = torch.device("mps")
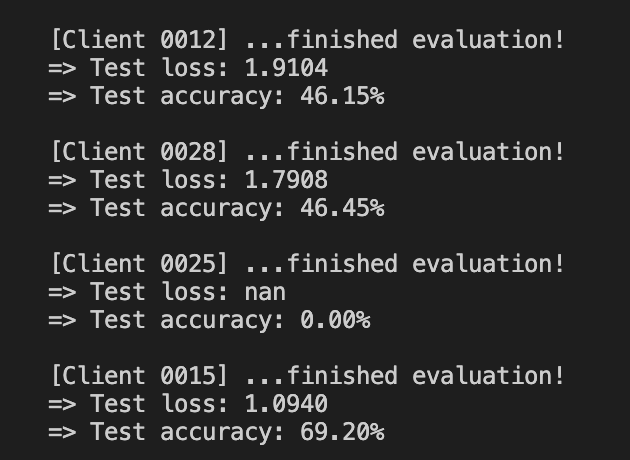
My loss would suddenly become NaN or Inf after a few iterations, like in the screenshot.
This problem arises after I upgrade my OS to MacOS Ventura. Already added non blocker: self.model.to(self.device, non_blocking=True)
Not sure what’s the issue here.