Hi everyone,
I’d like to predict if stock price increse or not with time series stock features ,which I think is a 2 class classfication task.
But i found that no matter how i change my hyper param,the loss won’t decrease and the accuracy won’t increase. Plz help me figure out where is my problem.
Here is my code
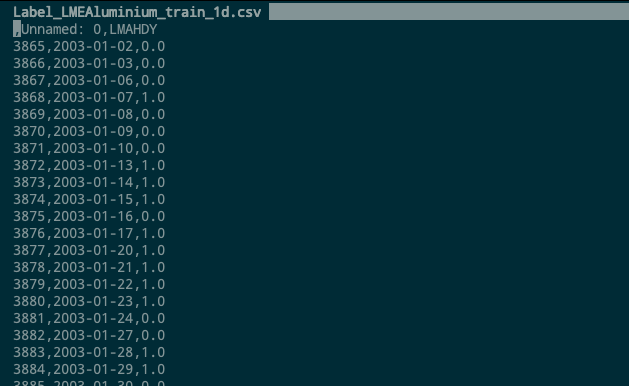
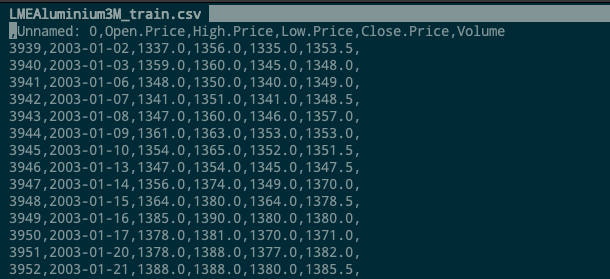
And dataset like this
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import numpy as np
import os
from sklearn.preprocessing import MinMaxScaler
DATA_DIR = '~/Train/Train_data'
METAL = 'LMECopper3M' #LMECopper3M,LMELead3M,LMENickle3M,LMETin3M,LMEZinc3M,LMEAluminium3M
PERIOD = '60d' #1d,20d,60d
VAL_LENGTH = 100
TIME_STEP = 100
HIDDEN_SIZE = 10
NUM_LAYERS = 2
TRAIN_EPOCH = 100
LR = 0.3
#train
def dataset():
files = os.listdir(DATA_DIR)
for file in files:
if file.startswith(METAL):
feature_all = pd.read_csv(os.path.join(DATA_DIR,file)).fillna(value=0)
if file.startswith('Label_' + METAL[:-2]) and file.endswith(PERIOD + '.csv'):
label_all = pd.read_csv(os.path.join(DATA_DIR,file))
feature = feature_all.iloc[:,2:].values
label = label_all.iloc[:,2].values
#feature scaling
sc = MinMaxScaler(feature_range = (0, 1))
feature = sc.fit_transform(feature)
#60 timesteps
feature_timesteps = []
label_timesteps = []
for i in range(TIME_STEP,len(feature_all)):
feature_timesteps.append(feature[i-TIME_STEP:i])
label_timesteps.append(label[i])
feature_timesteps,label_timesteps = torch.from_numpy(np.array(feature_timesteps)).transpose(1,2),torch.from_numpy(np.array(label_timesteps))
return feature_timesteps,label_timesteps
#model
class LSTM(nn.Module):
def __init__(self,input_size=60,hidden_size=100,num_layers=2,feature_dim=5,batch_first=True,class_dim=2):
super(LSTM,self).__init__()
self.lstm = nn.LSTM(input_size,hidden_size,num_layers,batch_first)
#self.fc = nn.Linear(feature_dim*hidden_size,class_dim)
self.fc = nn.Linear(hidden_size,class_dim)
def forward(self,train_dataset,hidden_state):
lstm_out,hidden_state = self.lstm(train_dataset,hidden_state)
hidden_size = hidden_state[-1].size(-1)
feature_dim = train_dataset[-1].size(0)
#lstm_out = lstm_out.reshape(-1,feature_dim*hidden_size)
lstm_out = self.fc(lstm_out[:,-1,:])
return lstm_out,hidden_state
def train(model,feature_timesteps,label_timesteps,optimizer,criterion,device):
model.train()
#hidden_state = (torch.zeros(2,5,100).to(device),torch.zeros(2,5,100).to(device))
hidden_state = None
for epoch in range(TRAIN_EPOCH):
optimizer.zero_grad()
feature_timesteps,label_timesteps = feature_timesteps.to(device).float(),label_timesteps.to(device).long()
out,hidden_state = model(feature_timesteps,hidden_state)
loss = criterion(out,label_timesteps)
loss.backward(retain_graph=True)
optimizer.step()
print('epoch {}, loss {}'.format(epoch,loss.item()))
##accuracy
correct = torch.zeros(1).squeeze().to(device)
total = torch.zeros(1).squeeze().cuda()
pred = torch.argmax(out,1)
correct += (pred == label_timesteps).sum().float()
total += len(label_timesteps)
print('Accuracy: %f'%((correct/total).cpu().detach().data.numpy()))
#for name, parms in model.named_parameters():
# print('-->name:', name, '-->grad_requirs:', parms.requires_grad, '--weight', torch.mean(parms.data), ' -->grad_value:', torch.mean(parms.grad))
def main():
feature_timesteps,label_timesteps = dataset()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTM(input_size=TIME_STEP,hidden_size=HIDDEN_SIZE,num_layers=NUM_LAYERS)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=LR,weight_decay=5e-4)
criterion = nn.CrossEntropyLoss()
train(model,feature_timesteps,label_timesteps,optimizer,criterion,device)
if __name__ == '__main__':
main()