I am using lstm to predict the wave height, but the loss error fluctuates very much, what could be the reason?

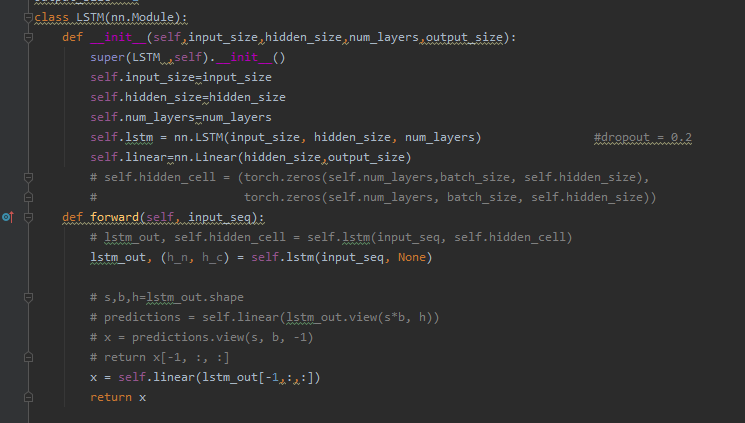
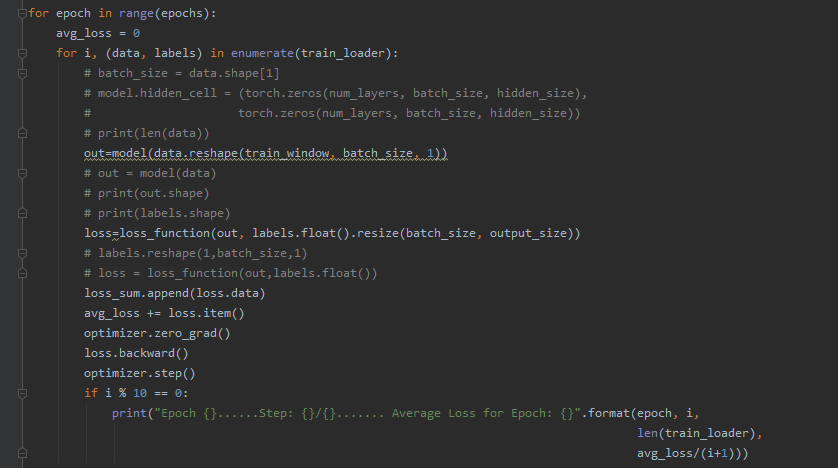
Are you using a synthetic dataset, which could have the same or a similar pattern?
Did you check the model output and could you see if the model was just predicting a single class?
Do you mean there may be a problem with the data, I am using lstm to predict the wave height.
This is just a guess and your model might just output a straight line, while the data might have waves.
This would create such a “wavy” loss curve, no?
You are right, the output is a straight line, how can I solve this problem
You could try to scale down the problem a bit, use a small data samples (e.g. only 10 samples), and try to overfit the model on this dataset by playing around with the hyperparameters, architecture, optimizer etc.
Once your model successfully predicts the small dataset, you could then try to scale it up again.