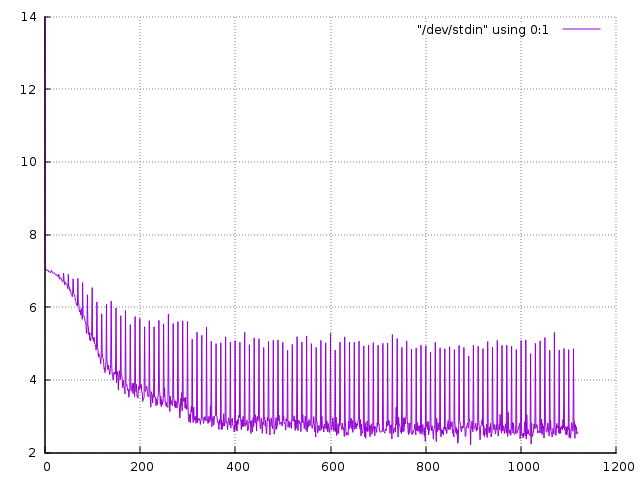
When I train my network on multiple machines (using DistributedDataParallel) I observe my loss exploding when I switch my network to evaluation using model.eval() and torch.no_grad().
When outside the torch.no_grad() context, I switch to model.train() and observe a loss that is way worse than what I was observing at the end of the epoch.
This only happens when using DistributedDataParallel.
Training
the spikes appear at the beginning of the epoch, just after the validation step. The loss at that moment is close to what I observe in validation. Has anyone an idea about what could be causing that ?
Hi Milas! This looks very odd. Is it possible that you’re seeing some data contamination between your training and validation datasets? The fact that you run with no_grad during evaluation mode, as well as setting model.eval() all sounds perfectly normal.
You say that if you run without DistributedDataParallel you don’t observe this issue? Does this happen for any number of processes > 1?
Thanks for your answer. This looks odd indeed. There is no contamination between the sets. Everything is in separated folders and the dataset class only gets the right folder.
I did try many things.
Even when I set to train, never switch to eval and only do training steps without ever going to the validation dataset this still occurs at the beginning of the epochs. I tried with either torch.utils.data.distributed.DistributedSampler or simply with random sampling without splitting the dataset between machines.
I am using filesystem synchronisation.
My code is fairly based on the imagenet example.
I am using batchnorm and have seen that it does not get properly synchronized but it should not be a problem I guess since the distribution of my samples should stay the same.
I do have some custom initialisations in the __init__ of my modules.
If I find something I will keep this thread updated.
I was looking at def train in DistributedDataParallel, more specifically these lines and am worried the slicing of replicas may be causing this. Looking at def train in nn.Module I don’t see how the train mode would be set on self.module. Can you try removing the slicing to ensure the train mode is set on every module replica (even if there aren’t any) and see what happens? Since the train mode controls whether or not you’re accumulating running stats in batch norm layers, this could explain both the regression and the recovery after a couple of iterations.
@pietern unfortunately it still occurs with the nightly. Tried to remove as many custom things as I could but it still happens. Perhaps having non homogeneous gpus is the issue ? Since I don’t control the machines the job is spawned on I usually end up on a mix of kepler and pascal architectures.
The train / eval modes probably have nothing to do with this since I tried switching to train at the very beginning and never switching again and it still occurs. Currently I am not using DDP but if I find where it goes wrong I will definitely update.
@Milas Thank you for the update. I doubt that heterogeneous GPUs is the issue… I would expect the numerical behavior to be largely identical across architectures. If you also mix library versions (e.g. cuDNN) this is more likely though.
torch.utils.data.distributed.DistributedSampler uses the epoch number as a seed to deterministically randomize the data to create coherent bigger batches (i.e. a different subsample of the dataset is seen each time through training and the samples do not overlap between the different training instances.)
Also do you scale the learning rate according to the number of instances you spawn ?